
Jeremy Schneider

Paranoid SQL Execution on Postgres
Suppose that you want to be completely over-the-top paranoid about making sure that when you execute some particular SQL statement on your Postgres database, you’re doing it in the safest and least risky way?
For example, suppose it’s the production database behind your successful startup’s main commercial website. If anything even causes queries to block/pause for a few minutes then people will quickly be tweeting about how they can’t place orders and it hurt both your company’s revenue and reputation.
You know that it’s really important to save regular snapshots and keep a history of important metrics. You’re writing some of your own code to capture a few specific stats like the physical size of your most important application tables or maybe the number of outstanding orders over time. Maybe you’re writing some java code that gets scheduled by quartz, or maybe some python code that you’ll run with cron.
Or another situation might be that you’re planning to make an update to your schema – adding a new table, adding a new column to an existing table, modifying a constraint, etc. You plan to execute this change as an online operation during the weekly period of lowest activity on the system – maybe it’s very late Monday night, if you’re in an industry that’s busiest over weekends.
How can you make sure that your SQL is executed on the database in the safest possible way?
Here are a few ideas I’ve come up with:
- Setting
connect_timeoutto something short, for example 2 seconds. - Setting
lock_timeoutto something appropriate. For example, 2ms on queries that shouldn’t be doing any locking. (I’ve seen entire systems brown-out because a “quick” DDL had to get in line behind an app transaction, and then all the new app transactions piled up behind the DDL that was waiting!) - Setting
statement_timeoutto something reasonable for the query you’re running – thus putting an upper bound on execution time. - Using an appropriate client-side timeout, for cases when the server fails to kill the query using
statement_timeout. For example, in Java the Statement class has native support for this. - When writing SQL, fully qualify names of tables and functions with the schema/namespace. (This can be a security feature; I have heard of attacks where someone manages to change the search_path for connections.)
- Check at least one explain plan and make sure it’s doing what you would expect it to be doing, and that it seems likely to be the most efficient way to get the information you need.
- Don’t use system views that join in unneeded data sources; go direct to needed raw relation or a raw function.
- Access each data source exactly once, never more than once. In that single pass, get all data that will be needed. Analytic or window functions are very useful for avoiding self-joins.
- Restrict the user to minimum needed privileges. For example, the
pg_read_all_statsrole on an otherwise unprivileged user might be useful. - Make sure your code has back-off logic for retries when failures or unexpected results are encountered.
- Prevent connection pile-ups resulting from database slowdowns or hangs. For example, by using a dedicated client-side connection pool with dynamic sizing entirely disabled or with a small max pool size.
- Run the query against a physical replica/hot standby (e.g. pulling a metric for the physical size of important tables) or logical copy (e.g. any query against application data), instead of running the query against the primary production database. (However, note that when
hot_standby_feedbackis enabled, long-running transactions on the PostgreSQL hot standby can still impact the primary system.) - For all DDL, carefully check the level of locking that it will require and test to get a feel for possible execution time. Watch out for table rewrites. Many DDLs that used to require a rewrite no longer do in current versions of PostgreSQL, but there are still a few out there. ALTER TABLE statements must be evaluated very carefully. Frankly ALTER TABLE is a bit notorious for being unclear about which incantations cause table rewrites and which ones don’t. (I have a friend who just tests every specific ALTER TABLE operation first on an empty table and then checks if pg_class changes show that a rewrite happened.)
What am I missing? What other ideas are out there for executing SQL in Postgres with a “paranoid” level of safety?
Note: see also Column And Table Redefinition With Minimal Locking
PostgreSQL Invalid Page and Checksum Verification Failed
At the Seattle PostgreSQL User Group meetup this past Tuesday, we got onto the topic of invalid pages in PostgreSQL. It was a fun discussion and it made me realize that it’d be worth writing down a bunch of the stuff we talked about – it might be interesting to a few more people too!
Invalid Page In BlockYou see an error message that looks like this:
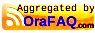
ERROR: invalid page in block 1226710 of relation base/16750/27244First and foremost – what does this error mean? I like to think of PostgreSQL as having a fairly strong “boundary” between (1) the database itself and (2) the operating system [and by extension everything else… firmware, disks, network, remote storage, etc]. PostgreSQL maintains page validity primarily on the way in and out of its buffer cache.
What does this mean in practice? Suppose there’s a physical memory failure and somehow the ECC parity is unable to detect it. This means that a little bit of physical memory on the server now has incorrect garbage and the correct data from that memory is lost.
- If the garbage bytes map to part of the kernel page cache, then when PostgreSQL tries to copy the page into it’s buffer cache then it will (if possible) detect that something is wrong, refuse to poison its buffer cache with this invalid 8k page, and error out any queries that require this page for processing with the ERROR message above.
- If the garbage bytes map to part of PostgreSQL’s database buffer cache, then PostgreSQL will quite happily assume nothing is wrong and attempt to process the data on the page. Results are unpredictable; probably all sorts of ERROR messages, crashes and failure modes could result – or maybe even incorrect data returned with no ERROR message at all. (Note that this is probably the case for nearly all software… and also note that ECC is pretty good.)
PostgreSQL has two main “validity checks” that it performs on pages. You can read the code in the function PageIsVerified() but I’ll summarize here. You can tell from your error message which validity check failed. It depends on whether you see a second additional WARNING right before the ERROR. The warning would look like this:
WARNING: page verification failed, calculated checksum 3482 but expected 32232- If the above warning is not present, this means the page header failed a basic sanity check. This could conceivably be caused by both problems inside and outside of PostgreSQL.
- If you see the above warning (page verification failed), this means the checksum recorded in the block did not match the checksum calculated for the block. This most likely indicates that there was a problem outside of (underneath) the database – operating system, memory, networking, storage, etc.
As of when I’m writing this article in 2019, the following basic sanity checks are performed on the page header:
- There are 32 bits reserved for page flag bits; at present only three are used and the other 29 bits should always be zero/off.
- Every page is divided into four parts (header, free space, tuples, special space). Offsets for the divisions are stored as 16-bit numbers in the page header; the offsets should go in order and should not have a value pointing off the page.
- The offset of the special space should always be aligned.
PostgreSQL version 9.3 (released in 2013) added the ability to calculate a checksum on data pages and store the checksum in the page. There are two inputs to the checksum: (1) every single byte of the data page, with zeros in the four bytes where the checksum will be stored later and (2) the page offset/address. This means that PostgreSQL doesn’t just detect if a byte is changed in the page – it also detects if a perfectly valid page gets somehow dropped into the wrong place.
Checksums are not maintained for blocks while they are in the shared buffers – so if you look at a buffer in the PostgreSQL page cache with pageinspect and you see a checksum value, note that it’s probably just leftover from the last read but wouldn’t have been maintained when the page was changed. The checksum is calculated and stamped onto the page when the page is written out of the buffer cache into the operating system page cache (remember the pages get flushed to disk later by a separate fsync call).
The checksum algorithm is specifically designed to take advantage of SIMD instructions. The slowest part of the algorithm is multiplication, so if possible PostgreSQL will be compiled to perform 32 multiplications at a time in parallel. In 2013 there were two platforms specifically documented to support this: x86 SSE4.1 and ARM NEON. The implementation is specifically tuned for optimal performance on x86 SSE. This is an important point actually – particularly for folks running PostgreSQL on embedded devices – PostgreSQL certainly compiles and works well on a lot of platforms, but evidently the checksum implementation is explicitly optimized to run the fastest on Intel. (To be clear… I think everyone should use checksums on every platform unless you have a really really good reason not to – just don’t be surprised if you start comparing benchmarks with Intel and you see a difference!)
For folks interested in digging a little more into the history… here’s the original commit using a CRC algorithm which never shipped in an actual PostgreSQL release (Simon Riggs, Jeff Davis and Greg Smith), here’s the subsequent commit introducing the FNV-1a algorithm instead of CRC which is what we still use today (Ants Aasma), and here’s the commit doing the major refactor which moved the algorithm into a header file for easier external use (Tom Lane).
More Ways To Check ValidityAt the SEAPUG meetup this led to a discussion about checking validity. Do checksums cover everything? (hint: no) Are there more ways we can validate our databases? (hint: yes)
I haven’t yet made a full list of which files are covered by checksums and which ones aren’t, but I know that not everything is. For example: I’m pretty sure that the visiblity map and SLRU files aren’t covered with checksums. But for what it’s worth, there are two extra tools we can use verification in PostgreSQL databases:
- The amcheck extension can scan a B-Tree index for a number of logical problems – for example, verifying that all B-Tree pages have items in “logical” order. (This could be useful, for example, if you’re not specifying ICU collation and you recently upgraded your operating system collation libraries… since PostgreSQL uses OS collation by default.)
- The pg_visibility_map extension includes two functions to check for corruption in the visibility map – pg_check_frozen() and pg_check_visible().
Finally, what if you actually run into a checksum failure? What should you do, and are there any additional tools you should know about?
First of all – on any database – there are a few things you should always do immediately when you see something indicating that a data corruption may have occurred:
- Verify that your backup retention and your log file retention are sufficiently long – I recommend at least a month (this is a Happiness Hint). You never know how long the investigation might take, or how long ago something important might have happened.
- Take a moment to articulate and write out the impact to the business. (Are important queries failing right now? Is this causing an application outage?) This seems small but it can be very useful in making decisions later. Don’t exaggerate the impact but don’t understate it either. It can also be helpful to note important timelines that you already know about. For example: management is willing to use yesterday’s backup and take a day of data loss to avoid an 12 hour outage, but not to avoid a 4 hour outage …or… management needs a status update at 11:00am Eastern Time.
- If there’s a larger team working on the system in question, communicate a freeze on changes until things are resolved.
- Make a list or inventory of all copies of the data. Backups, physical replicas or hot standbys, logical replicas, copies, etc. Sometimes the very process of making this list can immediately give you ideas for simple solutions (like checking if a hot standby has the block intact). The next thing you probably want to do is check all items in this list to see if they have a valid copy of the data in question. Do not take any actions to remediate the problem right away, collect all of the information first. The data you collect now might useful during RCA investigation after you’re back online.
- If there was one checksum failure, then you probably want to make sure there aren’t more.
- If it’s a small database, consider whether you can scan the whole thing and verify the checksum on every single block.
- If it’s a large database, consider whether you can at least scan all of the system/catalog tables and perhaps scan the tables which are throwing errors in their entirety. (PostgreSQL stops on the first error, so there isn’t an easy way to check if other blocks in the same table also have checksum problems.)
- A few general best practices… (1) have a second person glance at your screen before you execute any actual changes, (2) never delete anything but always rename/move instead, (3) when investigating individual blocks, also look at the block before and the block after to verify they look like what you’d normally expect, (4) test the remediation plan before running it in production, and (5) document everything. If you’ve never seen Paul Vallée’s FIT-ACER checklist then it’s worth reviewing.
There’s no single prescriptive process for diagnosing the scope of the problem and finding the right path forward for you. It involves learning what you need to know about PostgreSQL, a little creative thinking about possible resolutions, and balancing the needs of the business (for example, how long can you be down and how much data loss can you tolerate).
That being said, there are a few tools I know about which can be very useful in the process. (And there are probably more that I don’t know about; please let me know and I can add them to this list!)
Data investigation:Unix/Linux CommandsYou might be surprised at what you can do with the tools already installed on your operating system. I’ve never been on a unix system that didn’t have dd and od installed, and I find that many Linux systems have hexdump and md5sum installed as well. A few examples of how useful these tools are: dd can extract the individual block with invalid data on the primary server and extract the same block on the hot standby, then od/hexdump can be used to create a human-readable textual dump of the binary data. You can even use diff to find the differences between the blocks. If you have a standby cluster with storage-level replication then you could use md5sum to see at a glance if the blocks match. (Quick word of caution on comparing hot standbys: last I checked, PostgreSQL doesn’t seem to maintain the free space identically on hot standbys, so the checksums might differ on perfectly healthy blocks. You can still look at the diff and verify whether free space is the only difference.) Drawbacks: low-level utilities can only do binary dumps but cannot interpret the data. Also, utilities like dd are “sharp knives” – powerful tools which can cause damage if misused!
For a great example of using dd and od, read the code in Bertrand Drouvot‘s pg_toolkit script collection.Data investigation and checksum verification:
pg_filedumpThis is a crazy awesome utility and I have no idea why it’s not in core PostgreSQL. It makes an easy-to-read textual dump of the binary contents of PostgreSQL data blocks. You can process a whole file or just specify a range of blocks to dump. It can verify checksums and it can even decode the contents of the tuples. As far as I can tell, it was originally written by Patrick Macdonald at Red Hat some time in the 2000’s and then turned over to the PostgreSQL Global Development Group for stewardship around 2011. It’s now in a dedicated repository at git.postgresql.org and it seems that Tom Lane, Christoph Berg and Teodor Sigaev keep it alive but don’t invest heavily in it. Drawbacks: be aware that it doesn’t address the race condition with a running server (see Credativ pg_checksums below). For dumping only a block with a checksum problem, this is not an issue since the server won’t let the block into its buffer cache anyway.Checksum verification:
PostgreSQL pg_checksumsPostgreSQL itself starting in version 11 has a command-line utility to scan one relation or everything and verify the checksum on every single block. It’s called pg_verify_checksums in v11 and pg_checksums in v12. Drawbacks: first, this utility requires you to shut down the database before it will run. It will throw an error and refuse to run if the database is up. Second, you can scan a single relation but you can’t say which database it’s in… so if the OID exists in multiple databases, there’s no way to just scan the one you care about.Checksum verification:
Credativ pg_checksumsThe fine engineers of Credativ have published an enhanced version of pg_checksums which can verify checksums on a running database. It looks to me like the main case they needed to protect against was the race condition between pg_checksum reading blocks while the running PostgreSQL server was writing those same blocks. Linux of course work on a 4k page size; so if an 8k database page is half written when pg_checksum reads it then we will get a false positive. The version from credativ however is smart enough to deal with this. Drawbacks: check the github issues; there are a couple notable drawbacks but this project was only announced last week and all the drawbacks might be addressed by the time you read this article. Also, being based on the utility in PostgreSQL, the same limitation about scanning a single relation applies.
Note that both Credativ’s and PostgreSQL’s pg_checksums utilities access the control file, even when just verifying checksums. As a result, you need to make sure you compile against the same version of PostgreSQL code as the target database you’re scanning.Checksum verification:
Satoshi Nagayasu postgres-toolkitI’m not sure if this is still being maintained, but Satoshi Nagayasu wrote postgres-toolkit quite a long time ago which includes a checksum verification utility. It’s the oldest one I have seen so far – and it still compiles and works! (Though if you want to compile it on PostgreSQL 11 or newer then you need to use the patch in this pull request.) Satoshi’s utility also has the very useful capability of scanning an arbitrary file that you pass in – like pg_filedump but stripped down to just do the checksum verification. It’s clever enough to infer the segment number from the filename and scan the file, even if the file isn’t part of a PostgreSQL installation. This would be useful, for example, if you were on a backup server and wanted to extract a single file from your backup and check if the damaged block has valid checksum in the backup. Drawbacks: be aware that it doesn’t address the race condition with a running server.Checksum verification:
Google pg_page_verificationSimple program; you pass in a data directory and it will scan every file in the data directory to verify the checksums on all blocks. Published to Github in early 2018. Drawbacks: be aware that it doesn’t address the race condition with a running server. Probably superseded by the built-in PostgreSQL utilities.Mitigation:
PostgreSQL Developer OptionsPostgreSQL has hundreds of “parameters” – knobs and button you can use to configure how it runs. There are 294 entries in the pg_settings table on version 11. Buried in these parameters are a handful of “Developer Options” providing powerful (and dangerous) tools for mitigating data problems – such as ignore_checksum_failure, zero_damaged_pages and ignore_system_indexes. Read very carefully and exercise great care with these options – when not fully understood, they can have unexpected side effects including unintended data loss. Exercise particular care with the ignore_checksum_failure option – even if you set that in an individual session, the page will be readable to all connections… think of it as poisoning the buffer cache. That being said, sometimes an option like zero_damaged_pages is the fastest way to get back up and running. (Just make sure you’ve saved a copy of that block!) By the way… a trick to trigger a read of one specific block is to
SELECT * FROM table WHERE ctid='(blockno,1)'Mitigation:Unix/Linux CommandsI would discourage the use of dd to mitigate invalid data problems. It’s dangerous even for experienced engineers; simple mistakes can compound the problem. I can’t imagine a situation where this is a better approach than the zero_damaged_pages developer option and a query to read a specific block. That said, I have seen cases where dd was used to zero out a page. More About Data Investigation
In order to put some of this together, I’ll just do a quick example session. I’m running PostgreSQL 11.5 an on EC2 instance and I used dd to write a few evil bytes into a couple blocks of my database.
First, lets start by just capturing the information from the log files:
$ grep "invalid page" ../log/postgresql.log|sed 's/UTC.*ERROR//'
2019-10-15 19:53:37 : invalid page in block 0 of relation base/16385/16493
2019-10-16 22:26:30 : invalid page in block 394216 of relation base/16385/16502
2019-10-16 22:43:24 : invalid page in block 394216 of relation base/16385/16502
2019-11-05 23:55:33 : invalid page in block 394216 of relation base/16385/16502
2019-11-05 23:57:58 : invalid page in block 394216 of relation base/16385/16502
2019-11-05 23:59:14 : invalid page in block 262644 of relation base/16385/16502
2019-11-05 23:59:21 : invalid page in block 262644 of relation base/16385/16502
2019-11-05 23:59:22 : invalid page in block 262644 of relation base/16385/16502
2019-11-05 23:59:23 : invalid page in block 262644 of relation base/16385/16502
2019-11-06 00:01:12 : invalid page in block 262644 of relation base/16385/16502
2019-11-06 00:01:16 : invalid page in block 0 of relation base/16385/16493
2019-11-06 00:02:05 : invalid page in block 250 of relation base/16385/16492With a little command-line karate we can list each distinct block and see the first time we got an error on that block:
$ grep "invalid page" ../log/postgresql.log |
sed 's/UTC.*ERROR//' |
awk '{print $1" "$2" "$11" invalid_8k_block "$8" segment "int($8/131072)" offset "($8%131072)}' |
sort -k3,5 -k1,2 |
uniq -f2
2019-11-06 00:02:05 base/16385/16492 invalid_8k_block 250 segment 0 offset 250
2019-10-15 19:53:37 base/16385/16493 invalid_8k_block 0 segment 0 offset 0
2019-11-05 23:59:14 base/16385/16502 invalid_8k_block 262644 segment 2 offset 500
2019-10-16 22:26:30 base/16385/16502 invalid_8k_block 394216 segment 3 offset 1000 So we know that there are at least 4 blocks corrupt. Lets scan the whole data directory using Credativ’s pg_checksum (without shutting down the database) to see if there are any more blocks with bad checksums:
$ pg_checksums -D /var/lib/pgsql/11.5/data |& fold -s
pg_checksums: error: checksum verification failed in file
"/var/lib/pgsql/11.5/data/base/16385/16502.3", block 1000: calculated checksum
2ED4 but block contains 4EDF
pg_checksums: error: checksum verification failed in file
"/var/lib/pgsql/11.5/data/base/16385/16502.3", block 1010: calculated checksum
9ECF but block contains ACBE
pg_checksums: error: checksum verification failed in file
"/var/lib/pgsql/11.5/data/base/16385/16502.2", block 500: calculated checksum
5D6 but block contains E459
pg_checksums: error: checksum verification failed in file
"/var/lib/pgsql/11.5/data/base/16385/16493", block 0: calculated checksum E7E4
but block contains 78F9
pg_checksums: error: checksum verification failed in file
"/var/lib/pgsql/11.5/data/base/16385/16492", block 250: calculated checksum
44BA but block contains 3ABA
Checksum operation completed
Files scanned: 1551
Blocks scanned: 624158
Bad checksums: 5
Data checksum version: 1Ah-ha… there was one more bad checksum which didn’t show up in the logs! Next lets choose one of the bad blocks and dump the contents using unix command line tools.
$ dd status=none if=base/16385/16492 bs=8192 count=1 skip=250 | od -A d -t x1z -w16
0000000 00 00 00 00 e0 df 6b b0 ba 3a 04 00 0c 01 80 01 >......k..:......<
0000016 00 20 04 20 00 00 00 00 80 9f f2 00 00 9f f2 00 >. . ............<
0000032 80 9e f2 00 00 9e f2 00 80 9d f2 00 00 9d f2 00 >................<
0000048 80 9c f2 00 00 9c f2 00 80 9b f2 00 00 9b f2 00 >................<
0000064 80 9a f2 00 00 9a f2 00 80 99 f2 00 00 99 f2 00 >................<
0000080 80 98 f2 00 00 98 f2 00 80 97 f2 00 00 97 f2 00 >................<Here we see the page header and the beginning of the line pointers. One thing I think it’s easy to remember is that the first 8 bytes are the page LSN and the next 2 bytes are the page checksum. Notice that the page checksum bytes contain “ba 3a” which matches the error message from the scan above (3ABA). Sometimes it can be useful to know just the very top of the page even if you don’t remember anything else!
This is useful, but lets try the pg_filedump utility next. This utility takes a lot of options. In this example I’m going to ask it to verify the checksum (-k), only scan one block at offset 250 (-R 250 250) and even to decode the tuples (table row data) to a human-readable format (-D int,int,int,charN). There’s another argument (-f) that can even tell pg_filedump to show hexdump/od style raw data inline but I won’t demonstrate that here.
$ pg_filedump -k -R 250 250 -D int,int,int,charN base/16385/16492
*******************************************************************
* PostgreSQL File/Block Formatted Dump Utility - Version 11.0
*
* File: base/16385/16492
* Options used: -k -R 250 250 -D int,int,int,charN
*
* Dump created on: Fri Nov 8 21:48:38 2019
*******************************************************************
Block 250 ********************************************************
<Header> -----
Block Offset: 0x001f4000 Offsets: Lower 268 (0x010c)
Block: Size 8192 Version 4 Upper 384 (0x0180)
LSN: logid 0 recoff 0xb06bdfe0 Special 8192 (0x2000)
Items: 61 Free Space: 116
Checksum: 0x3aba Prune XID: 0x00000000 Flags: 0x0004 (ALL_VISIBLE)
Length (including item array): 268
Error: checksum failure: calculated 0x44ba.
<Data> ------
Item 1 -- Length: 121 Offset: 8064 (0x1f80) Flags: NORMAL
COPY: 15251 1 0
Item 2 -- Length: 121 Offset: 7936 (0x1f00) Flags: NORMAL
COPY: 15252 1 0
Item 3 -- Length: 121 Offset: 7808 (0x1e80) Flags: NORMAL
COPY: 15253 1 0That was the block header and the first few item. (Item pointer data is displayed first, then the table row data itself is displayed on the following line after the word COPY.) Looking down a little bit, we can even see where I wrote the bytes “budstuff” into a random location in this block – it turns out those bytes landed in the middle of a character field. This means that without checksums, PostgreSQL would not have thrown any errors at all but just returned an incorrect string the next time that row was queried!
COPY: 15297 1 0
Item 48 -- Length: 121 Offset: 2048 (0x0800) Flags: NORMAL
COPY: 15298 1 0
Item 49 -- Length: 121 Offset: 1920 (0x0780) Flags: NORMAL
COPY: 15299 1 0 badstuff
Item 50 -- Length: 121 Offset: 1792 (0x0700) Flags: NORMAL
COPY: 15300 1 0It’s immediately clear how useful this is (and easier to read <g>). The part where it decodes the table row data into a human readable form is an especially cool trick. Two notes about this.
- First, the lines are prefixed with the word COPY for a reason – they are actually intended to be formatted so you can grep on the word COPY and then use the “copy” command (or it’s psql cousin) to feed the data directly back into a staging table in the database for cleanup. How cool is that!
- Second, it can decode only a set of fairly standard data types and relation types.
$ pg_filedump -h
Version 11.0 (for PostgreSQL 11.x)
Copyright (c) 2002-2010 Red Hat, Inc.
Copyright (c) 2011-2018, PostgreSQL Global Development Group
Usage: pg_filedump [-abcdfhikxy] [-R startblock [endblock]]
[-D attrlist] [-S blocksize] [-s segsize] [-n segnumber] file
Display formatted contents of a PostgreSQL heap/index/control file
Defaults are: relative addressing, range of the entire file, block
size as listed on block 0 in the file
The following options are valid for heap and index files:
...
...
...
-D Decode tuples using given comma separated list of types
Supported types:
bigint bigserial bool char charN date float float4 float8 int
json macaddr name oid real serial smallint smallserial text
time timestamp timetz uuid varchar varcharN xid xml
~ ignores all attributes left in a tupleNow you see what happens when I start having fun… a quick update about our SEAPUG meetup this past Tuesday turned into a blog article that’s way too long. :) Hope it’s useful, and as always let me know what I can improve!
Update 9/16/21 – It was an oversight that I didn’t link it when I first published this post – but the PostgreSQL community wiki has a page on corruption. That page has a ton of good information and is definitely worth referencing.
Seattle PostgreSQL Meetup This Thursday: New Location
I’m looking forward to the Seattle PostgreSQL User Group meetup this Thursday (June 20, 2019) at 5:30pm! We’re going to get an early sneak peek at what’s coming later this year in PostgreSQL’s next major release. The current velocity of development in this open source community is staggering and this is an exciting and valuable opportunity to keep up with where PostgreSQL is going next.
One thing that’s a bit unusual about this meetup is the new location and late timing of the announcement. I think it’s worth a quick blog post to mention the location: for some people this new location might be a little more accessible than the normal spot (over at the Fred Hutch).
The meetup this week will be closer to downtown at 2201 6th Avenue (the building says “Blanchard Plaza” above the entrance): right next to the Spheres, easily accessible from public transportation and free parking across the street.

If you live or work in Seattle and you’re interested in databases but you don’t normally attend the Seattle PostgreSQL User Group, it’s worth checking if this location might be more convenient and make the visit worthwhile.
Bring any database question you have – there are people here who know PostgreSQL well enough to answer anything you can throw at them! Also, as always, some pizza and drinks will be provided. Hope to see you there!
PostgresConf 2019 Training Days
 It feels like PostgresConf in New York is in full swing, even though the main tracks haven’t even started yet!
It feels like PostgresConf in New York is in full swing, even though the main tracks haven’t even started yet!
(Oh, and by the way, as of this morning I heard there are still day-passes available for those who haven’t yet registered for the conference… and then you can come hear a great session about Wait Events in PostgreSQL this Thursday at 4:20pm!)
The first two days of PostgresConf are summits, tutorials and training sessions. A good chunk of my day today was helping out with Scott Mead’s intensive 3 hour hands-on lab Setting up PostgreSQL for Production in AWS – but outside of that I’ve managed to drop in to a number of other sessions that sounded interesting. I did my best to take down some notes so I could share a few highlights.
Monday March 18Personally, my favorite session on Monday was Brent Bigonger’s session. He’s a database engineer at Amazon who was involved in migrating their Inventory Management System to Aurora PostgreSQL. I always love hearing good stories (part of why I’ve always been a fan of user groups) – this presentation gave a nice high level overview of the business, a review of the planning and execution process for the migration, and lots of practical lessons learned.
- Some of the tips were things people are generally familiar with – like NULLs behaving differently and the importance of performance management with a tool like Performance Insights.
- My favorite tip is getting better telemetry by instrumenting SQL with comments (SELECT /* my-service-call-1234 */ …) which reminded me of something I also read in Baron Schwartz’s recently updated e-book on observable systems: “including implicit data in SQL.”
- A great new tip (to me) was the idea of creating a heartbeat table as one more safety check in a replication process. You can get a sense for lag by querying the table and you can also use it during a cutover to get an extra degree of assurance that no data was missed.
- Another general point I really resonated with: Brent gave a nice reminder that a simple solution which meets the business requirements is better than a sophisticated or complex solution that goes beyond what the business really needs. I feel tempted on occasion to leverage architectures because they are interesting – and I always appreciate hearing this reiterated!
On the AWS track, aside from Brent’s session, I caught a few others: Jim Mlodgenski giving a deep dive on Aurora PostgreSQL architecture and Jim Finnerty giving a great talk on Aurora PostgreSQL performance tuning and query plan management. It’s funny, but I think my favorite slide from Finnerty’s talk was actually one of the simplest and most basic; he had a slide that just had high-level list of steps for performance tuning. I don’t remember the exact list on that slide at the moment, but the essential process: (1) identify to top SQL (2) EXPLAIN to get the plan (3) make improvements to the SQL and (4) test and verify whether the improvements actually had the intended effect.
Other sessions I dropped into:
- Alvaro Hernandez giving an Oracle to PostgreSQL Migration Tutorial. I love live demos (goes along with loving hands on labs) and so this session was a hit with me – I wasn’t able to catch the whole thing but I did catch a walk-through of ora2pg.
- Avinash Vallarapu giving an Introduction to PostgreSQL for Oracle and MySQL DBAs. When I slipped in, he was just wrapping up a section on hot physical backups in PostgreSQL with the pg_basebackup utility. After that, Avi launched into a section on MVCC in PostgreSQL – digging into transaction IDs and vacuum, illustrated with block dumps and the pageinspect extension. The part of this session I found most interesting was actually a few of the participant discussions – I heard lively discussions about what extensions are and about comparisons with RMAN and older versions of Oracle.
As I said before, a good chunk of my morning was in Scott’s hands-on lab. If you ever do a hands-on lab with Scott then you’d better look out… he did something clever there: somewhere toward the beginning, if you followed the instructions correctly, then you would be unable to connect to your database! Turns out this was on purpose (and the instructions actually tell you this) – since people often have this particular problem connecting when they first start on out RDS, Scott figured he’d just teach everyone how to fix it. I won’t tell you what the problem actually is though – you’ll have to sign up for a lab sometime and learn for yourself. :)
As always, we had a lot of really interesting discussions with participants in the hands-on lab. We talked about the DBA role and the shared responsibility model, about new tools used to administer RDS databases in lieu of shell access (like Performance Insights and Enhanced Monitoring), and about how RDS helps implement industry best practices like standardization and automation. On a more technical level, people were interested to learn about the “pgbench” tool provided with postgresql.
In addition to the lab, I also managed to catch part of Simon Riggs’ session Essential PostgreSQL11 Database Administration – in particular, the part about PostgreSQL 11 new features. One interesting new thing I learned was about some work done specifically around the performance of indexes on monotonically increasing keys.
Interesting Conversations Of course I learned just as much outside of the sessions as I learned in the sessions. I ended up eating lunch with Alexander Kukushkin who helped facilitate a 3 hour hands-on session today about Understanding and implementing PostgreSQL High Availability with Patroni and enjoyed hearing a bit more about PostgreSQL at Zalando. Talked with a few people from a government organization who were a long-time PostgreSQL shop and interested to hear more about Aurora PostgreSQL. Talked with a guy from a large financial and media company about flashback query, bloat and vacuum, pg_repack, parallel query and partitioning in PostgreSQL.
Of course I learned just as much outside of the sessions as I learned in the sessions. I ended up eating lunch with Alexander Kukushkin who helped facilitate a 3 hour hands-on session today about Understanding and implementing PostgreSQL High Availability with Patroni and enjoyed hearing a bit more about PostgreSQL at Zalando. Talked with a few people from a government organization who were a long-time PostgreSQL shop and interested to hear more about Aurora PostgreSQL. Talked with a guy from a large financial and media company about flashback query, bloat and vacuum, pg_repack, parallel query and partitioning in PostgreSQL.
And of course lots of discussions about the professional community. Met PostgresConf conference volunteers from California to South Africa and talked about how they got involved in the community. Saw Lloyd and chatted about the Seattle PostgreSQL User Group.
The training and summit days are wrapping up and now it’s time to get ready for the next three days: keynotes, breakout sessions, exposition, a career fair and more! I can’t wait. :)
Column And Table Redefinition With Minimal Locking
TLDR: Note to future self… (1) Read this before you modify a table on a live PostgreSQL database. If you do it wrong then your app might totally hang. There is a right way to do it which avoids that. (2) Especially remember the lock_timeout step. Many blog posts around the ‘net are missing this and it’s very important.
Yesterday I was talking to some PostgreSQL users (who, BTW, were doing rather large-scale cool stuff in PG) and they asked a question about making schema changes with minimal impact to the running application. They were specifically curious about changing a primary key from INT to BIGINT. (Oh, you are making all your new PK fields BIGINT right?)
And then, low and behold, I discovered a chat today on the very same topic. Seemed useful enough to file away on my blog so that I can find it later. BTW I got permission from Jim Nasby, Jim F and Robins Tharakan to blame them for this… ;)
Most useful part of the chat was how to think about doing table definition changes in PostgreSQL with minimal application impact due to locking:
- Use lock_timeout.
- Can be set at the session level.
- For changes that do more than just a quick metadata update, work with copies.
- Create a new column & drop old column instead of modifying.
- Or create a new table & drop old table.
- Use triggers to keep data in sync.
- Carefully leverage transactional DDL (PostgreSQL rocks here!) to make changes with no windows for missing data.
We can follow this line of thought even for a primary key – creating a unique index on the new column, using existing index to update table constraints, then dropping old column.
One of the important points here is making sure that operations which require locks are metadata-only. That is, they don’t need to actually modify any data (while holding said lock) for example rewriting or scanning the table. We want these ops to run very very fast, and even time out if they still can’t run fast enough.
A few minutes on google yields proof that Jim Nasby was right: lots of people have already written up some really good advice about this topic. Note that (as always) you should be careful about dates and versions in stuff you find yourself. Anything pre-2014 should be scrutinized very carefully (PostgreSQL has change a lot since then); and for the record, PostgreSQL 11 changes this specific list again (and none of these articles seem to be updated for pg11 yet). And should go without saying, but test test test…
- This article from BrainTree is my favorite of what I saw this morning. Concise yet clear list of green-light and red-light scenarios, with workaround for all the red lights.
- Add a new column, Drop a column, Add an index concurrently, Drop a constraint (for example, non-nullable), Add a default value to an existing column, Add an index, Change the type of a column, Add a column with a default, Add a column that is non-nullable, Add a column with a unique constraint, VACUUM FULL
- Citus has a practical tips article that’s linked pretty widely.
- adding a column with a default value, using lock timeouts, Create indexes, Taking aggressive locks, Adding a primary key, VACUUM FULL, ordering commands
- assembled a list in 2016 which is worth reviewing.
- Add a new column, Add a column with a default, Add a column that is non-nullable, Drop a column, Change the type of a column, Add a default value to an existing column, Add an index, Add a column with a unique constraint, Drop a constraint, VACUUM FULL, ALTER TABLE SET TABLESPACE
- Joshua Kehn put together a good article in late 2017 that especially illustrates the importance of using lock_timeout (though he doesn’t mention it in the article)
- Default values for new columns, Adding a default value on an existing column, Concurrent index creation, ALTER TABLE, importance of typical transaction length
For fun and posterity, here’s the original chat (which has a little more detail) where they gave me these silly ideas:
[11/08/18 09:01] Colleague1: I have a question with regard to APG. How can we make DDL modifications to a table with minimalistic locking (downtime)?
[11/08/18 09:31] Jim N: It depends on the modification you're trying to make. Many forms of ALTER TABLE are very fast. Some don't even require an exclusive lock.
[11/08/18 09:32] Jim N: What you have to be careful of are alters that will force a rewrite of the entire table. Common examples of that are adding a new column that has a default value, or altering the type of an existing column.
[11/08/18 09:33] Jim N: What I've done in the past for those scenarios is to create a new field (that's null), put a before insert or update trigger on the table to maintain that field.
[11/08/18 09:33] Jim N: Then run a "backfill" that processes a few hundred / thousand rows per transaction, with a delay between each batch.
[11/08/18 09:34] Jim N: Once I know that all rows in the table have been properly updated, drop the old row, and maybe mark the new row as NOT NULL.
[11/08/18 09:43] Jim N: btw, I know there's been a talk about this at a conference in the last year or two...
[11/08/18 09:49] Jim F: What happens at the page level if the default value of an ALTER TABLE ADD COLUMN is null? Once upon a time when I worked at [a commercialized fork of PostgreSQL], which was built on a version of PostgreSQL circa 2000, I recall that the table would be versioned. This was a pure metadata change, but the added columns would be created for older-version rows on read, and probably updated on write. Is that how it currently works?
[11/08/18 09:55] Jim N: Jim F in essence, yes.
[11/08/18 09:56] Jim N: Though I wouldn't describe it as being "versioned"
[11/08/18 09:57] Jim N: But because columns are always added to the end of the tuple (and we never delete from pg_attribute), heap_deform_tuple can detect if a tuple is "missing" columns at the end of the tuple and just treat them as being null.
[11/08/18 09:57] Jim N: At least I'm pretty sure that's what's going on, without actually re-reading the code right now. 😉
[11/08/18 10:08] Jim F: does it work that way for non-null defaults as well? that would create a need for versioning, if the defaults changed at different points in time
[11/08/18 10:08] Robins: While at that topic.... Postgres v11 now has the feature to do what Jim F was talking about (even for non-NULLs). Although as Jim Nasby said, you still need to be careful about which (other) kind of ALTERs force a rewrite and use the Trigger workaround. "Many other useful performance improvements, including the ability to avoid a table rewrite for ALTER TABLE ... ADD COLUMN with a non-null column default"
[11/08/18 10:08] Jim F: exactly...
Did we get anything wrong here? Do you disagree? Feel free to comment. :)
This Week in PostgreSQL – May 31
Since last October I’ve been periodically writing up summaries of interesting content I see on the internet related to PostgreSQL (generally blog posts). My original motivation was just to learn more about PostgreSQL – but I’ve started sharing them with a few colleagues and received positive feedback. Thought I’d try posting one of these digests here on the Ardent blog – who knows, maybe a few old readers will find it interesting? Here’s the update that I put together last week – let me know what you think!
Hello from California!
Part of my team is here in Palo Alto and I’m visiting for a few days this week. You know… for all the remote work I’ve done over the years, I still really value this in-person, face-to-face time. These little trips from Seattle to other locations where my teammates physically sit are important to me.
This is also part of the reason I enjoy user groups and conferences so much. They’re opportunities to meet with other PostgreSQL users in real life. In fact – at this very moment – one of the most important PostgreSQL conferences in the world is happening: PgCon! Having attended a few other conferences over the past year, I’m holding down the fort in the office this week in order to send a bunch of other teammates… but you can be sure I’m keeping an eye on twitter. :)
https://www.pgcon.org/2018/
https://twitter.com/search?l=&q=pgcon%20OR%20pgcon_org
=====
In the meantime, lets get busy with the latest updates from the postgresql virtual world. First of all, I think the biggest headline is that (just in time for pgcon) we have the first official beta version of PostgreSQL 11! The release announcement headlines with major partitioning enhancements, more parallelism, a feature to speed up SQL execution by compiling certain operations on-demand into native machine code (JIT/Just-In-Time compilation), and numerous SQL enhancements. You can also read the first draft of the release notes. This is the time to start testing and give feedback to the development community!
https://www.postgresql.org/about/news/1855/
https://www.postgresql.org/docs/devel/static/release-11.html
Closely related to this, there’s one other really big headline that I’m excited about: the new AWS RDS Preview Environment. You can now try out the new pg11 features ahead of time with a single click! In part because the development community is so awesome, the first database available in the RDS Preview Environment is PostgreSQL. And the official PostgreSQL 11 beta release is _already_ available on RDS!! Personally I’m hoping that this benefits the community by getting more people to test and give feedback on new features being built for PostgreSQL 11. I hope it will make a great database even better.
https://aws.amazon.com/rds/databasepreview/
https://forums.aws.amazon.com/ann.jspa?annID=5788 (pg11 beta announcement)
Outside of the RDS and PG11-related stuff, I saw one other headline that I thought might be worth mentioning. On May 29, IBM published a blog post that caught my attention, featuring EnterpriseDB as an IBM partner on their Private Cloud deployments. You might not realize just how much PostgreSQL is being used and sold by IBM… but there’s Compose, ElephantSQL, and now EDB in the mix.
https://www.ibm.com/blogs/think/2018/05/next-enterprise-platform/
Part of the reason I took note of this was that I remember just last November when HPE ran a similar announcement, partnering with EDB on their on-premise subscription-based GreenLake platform.
https://news.hpe.com/hpe-expands-pay-per-use-it-to-key-business-workloads/
So it seems to me that EDB is doing some nice work at building up the PostgreSQL presence in the enterprise world – which I’m very happy to see. To be clear, this isn’t necessarily new… does anyone remember vPostgres?
Nonetheless, it feels to me like the ball is moving forward. It feels like PostgreSQL maturity and adoption are continually progressing at a very healthy pace.
=====
Moving on from headlines, lets get to the real stuff – the meaty technical articles. :)
First up, who likes testing and benchmarking? One of my favorite activities, truth be told! So I can’t quite convey just how excited I am about the preview release of Kevin Closson’s pgio testing kit. For those unfamiliar, Kevin has spent years refining his approach for testing storage through database I/O paths. Much work was done in the past with Oracle databases, and he calls his method SLOB. I’m excited to start using this kit for exploring the limits of storage through PostgreSQL I/O paths too.
Right after Kevin published that post, Franck Pachot followed up with a short article using pgio to look at the impact of the ext4 “sync” filesystem option (made relevant by the recently disclosed flaws in how PostgreSQL has been interacting with Linux’s implementation of fsync).
https://blog.dbi-services.com/postgres-the-fsync-issue-and-pgio-the-slob-method-for-postgresql/
In addition to Kevin’s release of PGIO, I also saw three other generally fun technical articles. First, Kaarel Moppel from Cybertec published an article showing much lower-than-expected impact of pl/pgsql triggers on a simple pgbench execution. Admittedly, I want to poke around at this myself, having seen a few situations myself where the impact seemed higher. Great article – and it certainly got some circulation on twitter.
https://www.cybertec-postgresql.com/en/are-triggers-really-that-slow-in-postgres/
Next, Sebastian Insausti has published an article explaining PostgreSQL streaming replication. What I appreciate the most about this article is how Sebastian walks through the history of how streaming replication was developed. That context is so important and helpful!
https://severalnines.com/blog/postgresql-streaming-replication-deep-dive
Finally, the requisite Vacuum post. :) This month we’ve got a nice technical article from Sourabh Ghorpade on the Gojek engineering team. Great high-level introduction to vacuuming in general, and a good story about how their team narrowly averted an “xid wraparound” crisis.
https://blog.gojekengineering.com/postgres-autovacuum-tuning-394bb99fe2c0
=====
We’ve been following Dimitri Fontaine’s series on PostgreSQL data types. Well sadly (but inevitably) he has brought the series to a close. On May 24, Dimitri published a great summary of the whole data type series – this definitely deserves to be on every developer’s short list of PostgreSQL bookmarks!
https://tapoueh.org/blog/2018/05/postgresql-data-types/
But while we’re talking about data types, there were two more related articles worth pointing out this time around. First, Berend Tober from SeveralNines published a nice article back on the 9th about the serial data type in PostgreSQL. This is an integer type that automatically comes with not-null constraints and auto-assignment from a sequence.
https://severalnines.com/blog/overview-serial-pseudo-datatype-postgresql
Secondly, Hans-Jürgen Schönig from Cybertec gives a nice overview of mapping data types from Oracle to PosgreSQL. He has a little paragraph in there about mapping Oracle numbers to PostgreSQL integers and numerics. That little paragraph probably deserves triple-bold-emphesis. Automatic mapping of every number column to PostgreSQL numeric has been cause for many, many performance woes in PostgreSQL databases!
https://www.cybertec-postgresql.com/en/mapping-oracle-datatypes-to-postgresql/
=====
For something that might be relevant to both developers and DBAs, I have a couple articles about SQL tuning. First, Brian Fehrle has written a great tuning introduction for the severalnines blog. His starting point is pg_stat_activity and the explain SQL command; exactly the same as my starting point. :)
https://severalnines.com/blog/why-postgresql-running-slow-tips-tricks-get-source
Next up, Louise Grandjonc from France has published a series of articles called “understanding EXPLAIN“. Did you ever wonder why there are _two_ numbers reported for execution time of each step? Louise answers this question and many more in the these four articles!
http://www.louisemeta.com/blog/explain/
http://www.louisemeta.com/blog/explain-2/
http://www.louisemeta.com/blog/explain-3/
http://www.louisemeta.com/blog/explain-4/
=====
Moving down the stack a little more, there were two articles about monitoring that seem worth passing along. Datadog has put out a lot of articles about monitoring recently. I hadn’t mentioned it before, but Emily Chang gave us yet another one back on April 12. As usual, I’m impressed with the level of quality in this thorough article which is specifically focused on PostgreSQL on RDS. I especially appreciated the key metrics, things I’ve used myself to characterize workloads.
https://www.datadoghq.com/blog/aws-rds-postgresql-monitoring/
Earlier I mentioned the severalnines blog post about replication – and the pgDash team published a nice article on May 2 about monitoring replication. The give another nice general architectural overview of replication as well.
https://pgdash.io/blog/monitoring-postgres-replication.html
=====
In my last update, I closed with a few articles about pgpool on the severalnines blog. It seemed worth mentioning that they have published a third, final article for their series.
https://severalnines.com/blog/guide-pgpool-part-three-hints-observations
Also, I spotted an article about pgpool on the AWS database blog too. While focused on Aurora PostgreSQL, there’s plenty to be learned about using pgpool with regular PostgreSQL here.
Along those lines, most people know about the other popular PostgreSQL connection pooler, pgbouncer. This is the connection pooler which is used by Gulcin Yildirim’s near-zero-downtime ansible-based upgrade tool, pglupgrade. He’s written a few articles about his process recently, and being a big ansible fan I’ve been following along.
https://blog.2ndquadrant.com/near-zero-downtime-automated-upgrades-postgresql-clusters-cloud/
https://blog.2ndquadrant.com/near-zero-downtime-automated-upgrades-postgresql-clusters-cloud-part-ii/
But I wonder if the landscape is about to change? Yesterday the Yandex team announced that they have built and released a new load balancer to address limitations in pgpool and pgbouncer. I’ll be very interested to see what happens with odyssey!
https://www.postgresql.org/message-id/C9D1137E-F2A7-4307-B758-E5ED5559FFCA@simply.name (announcement)
https://github.com/yandex/odyssey
And that wraps things up for this edition.
Have a great week and keep learning!
Understanding CPU on AIX Power SMT Systems
This month I worked with a chicagoland company to improve performance for eBusiness Suite on AIX. I’ve worked with databases running on AIX a number of times over the years now. Nevertheless, I got thrown for a loop this week.
TLDR: In the end, it came down to a fundamental change in resource accounting that IBM introduced with the POWER7 processor in 2010. The bottom line is twofold:
- if SMT is enabled then the meaning of CPU utilization numbers is changed. the CPU utilization numbers for individual processes mean something completely new.
- oracle database 11.2.0.3 (I haven’t tested newer versions but they might also be affected) is not aware of this change. as a result, all CPU time values captured in AWR reports and extended SQL traces are wrong and misleading if it’s running on AIX/POWER7/SMT. (I haven’t tested CPU time values at other places in the database but they might also be wrong.)
On other unix operating systems (for example Linux with Intel Hyper-Threading), the CPU numbers for an individual process reflect the time that the process spent on the CPU. It’s pretty straightforward: 100% means that the process is spending 100% of its time on the logical CPU (a.k.a. thread – each hardware thread context on a hyper-threaded core appears as a CPU in Linux). However AIX with SMT is different. On AIX, when you look at an individual process, the CPU utilization numbers reflect IBM’s opinion about what percentage of physical capacity is being used.
Why did IBM do this? I think that their overall goal was to help us in system-wide monitoring and capacity planning – however it came at the expense of tuning individual processes. They are trying to address real shortcomings inherent to SMT – but as someone who does a lot of performance optimization, I find that their changes made my life a lot more difficult!
HistoryLs Cheng started a conversation in November 2012 on the Oracle-L mailing list about his database on AIX with SMT enabled, where the CPU numbers in the AWR report didn’t even come close to adding up correctly. Jonathan Lewis argued that double-counting was the simplest explanation while Karl Arao made the case for time in the CPU run queue. A final resolution as never posted to the list – but in hindsight it was almost certainly the same problem I’m investigating in this article. It fooled all of us. CPU intensive Oracle workloads on AIX/Power7/SMT most frequently misleads performance experts into thinking there is a CPU runqueue problem at the OS level. In fact, after researching for this article I went back and looked at my own final report from a consulting engagement with an AIX/SMT client back in August 2011 and realized that I made this mistake myself!
As far as I’m aware, Marcin Przepiorowski was the first person to really “crack” the case when and he researched and published a detailed explanation back in February 2013 with his article Oracle on AIX – where’s my cpu time?. Marcin was tipped off by Steve Pittman’s detailed explanation published in a December 2012 article Understanding Processor Utilization on Power Systems – AIX. Karl Arao was also researching it back in 2013 and published a lot of information on his tricky cpu aix stuff tiddlywiki page. Finally, Graham Wood was digging into it at the same time and contributed to several conversations amongst oak table members. Just to be clear that I’m not posting any kind of new discovery! :)
However – despite the fact that it’s been in the public for a few years – most people don’t understand just how significant this is, or even understand exactly what the problem is in technical terms. So this is where I think I can make a contribution: by giving a few simple demonstrations of the behavior which Steve, Marcin and Karl have documented.
CPU and MultitaskingI recently spent a few years leading datbase operations for a cloud/SaaS company. Perhaps one of the most striking aspects of this job was that I had crossed over… from being one of the “young guys” to being one of the “old guys”! I certainly wasn’t the oldest guy at the company but more than half my co-workers were younger than me!
Well my generation might be the last one to remember owning personal computers that didn’t multitask. Ok… I know that I’m still working alongside plenty of folks who learned to program on punch-cards. But at the other end of the spectrum, I think that DOS was already obsolete when many of my younger coworkers starting using technology! Some of you younger devs started with Windows 95. You’ve always had computers that could run two programs in different windows at the same time.
Sometimes you take a little more notice of tech advancements you personally experience and appreciate. I remember it being a big deal when my family got our first computer that could do more than one thing at a time! Multitasking (or time sharing) is not a complicated concept. But it’s important and foundational.
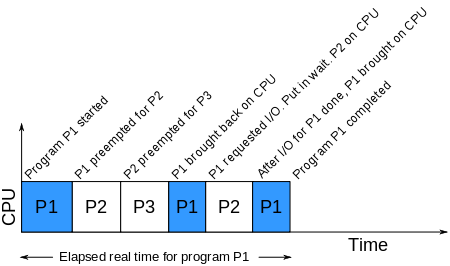
CPU Time on Single CPU Multi Tasking System
CPU color time for program P1
So obviously (I hope), if there are multiple processes and only a single CPU then the processes will take turns running. There are some nuances around if, when and how the operating system might force a process to get off the CPU but the most important thing to understand is just the timeline pictured above. Because for the rest of this blog post we will be talking about performance and time.
Here is a concrete example of the illustration above: one core in my laptop CPU can copy 13GB of data through memory in about 4-5 seconds:
$ time -p taskset 2 dd if=/dev/zero of=/dev/null bs=64k count=200k
204800+0 records in
204800+0 records out
13421772800 bytes (13 GB) copied, 4.73811 s, 2.8 GB/s
real 4.74
user 0.13
sys 4.54
The “taskset” command on linux pins a command on a specific CPU #2 – so “dd” is only allowed to execute on that CPU. This way, my example runs exactly like the illustration above, with just a single CPU.
What happens if we run two jobs at the same time on that CPU?
$ time -p taskset 2 dd if=/dev/zero of=/dev/null bs=64k count=200k &
[1] 18740
$ time -p taskset 2 dd if=/dev/zero of=/dev/null bs=64k count=200k &
[2] 18742
204800+0 records in
204800+0 records out
13421772800 bytes (13 GB) copied, 9.25034 s, 1.5 GB/s
real 9.25
user 0.09
sys 4.57
204800+0 records in
204800+0 records out
13421772800 bytes (13 GB) copied, 9.22493 s, 1.5 GB/s
real 9.24
user 0.12
sys 4.54
[1]- Done time -p taskset 2 dd if=/dev/zero of=/dev/null bs=64k count=200k
[2]+ Done time -p taskset 2 dd if=/dev/zero of=/dev/null bs=64k count=200k
Naturally, it takes twice as long – 9-10 seconds. I ran these commands on my linux laptop but the same results could be observed on any platform. By the way, notice that the “sys” number was still 4-5 seconds. This means that each process was actually executing on the CPU for 4-5 seconds even though it took 9-10 seconds of wall clock time.
The “time” command above provides a summary of how much real (wall-clock) time has elapsed and how much time the process was executing on the CPU in both user and system modes. This time is tracked and accounted for by the operating system kernel. The linux time() command uses the wait4() system call to retrieve the CPU accounting information. This can be verified with strace:
$ strace -t time -p dd if=/dev/zero of=/dev/null bs=64k count=200k
10:07:06 execve("/usr/bin/time", ["time", "-p", "dd", "if=/dev/zero", "of=/dev/null", \
"bs=64k", "count=200k"], [/* 48 vars */]) = 0
...
10:07:06 clone(child_stack=0, flags=CLONE_CHILD_CLEARTID|CLONE_CHILD_SETTID|SIGCHLD, \
child_tidptr=0x7f8f841589d0) = 12851
10:07:06 rt_sigaction(SIGINT, {SIG_IGN, [INT], SA_RESTORER|SA_RESTART, 0x7f8f83be90e0}, \
{SIG_DFL, [], 0}, 8) = 0
10:07:06 rt_sigaction(SIGQUIT, {SIG_IGN, [QUIT], SA_RESTORER|SA_RESTART, 0x7f8f83be90e0}, \
{SIG_IGN, [], 0}, 8) = 0
10:07:06 wait4(-1,
204800+0 records in
204800+0 records out
13421772800 bytes (13 GB) copied, 4.66168 s, 2.9 GB/s
[{WIFEXITED(s) && WEXITSTATUS(s) == 0}], 0, {ru_utime={0, 108000}, \
ru_stime={4, 524000}, ...}) = 12851
10:07:11 --- SIGCHLD {si_signo=SIGCHLD, si_code=CLD_EXITED, si_pid=12851, si_uid=1000, \
si_status=0, si_utime=10, si_stime=454} ---
10:07:11 rt_sigaction(SIGINT, {SIG_DFL, [INT], SA_RESTORER|SA_RESTART, 0x7f8f83be90e0}, \
{SIG_IGN, [INT], SA_RESTORER|SA_RESTART, 0x7f8f83be90e0}, 8) = 0
10:07:11 rt_sigaction(SIGQUIT, {SIG_IGN, [QUIT], SA_RESTORER|SA_RESTART, 0x7f8f83be90e0}, \
{SIG_IGN, [QUIT], SA_RESTORER|SA_RESTART, 0x7f8f83be90e0}, 8) = 0
10:07:11 write(2, "r", 1r) = 1
10:07:11 ...
Two notes about this. First, you’ll see from the timestamps that there’s a 5 second pause during the wait4() syscall and the output from “dd” interrupts its output. Clearly this is when “dd” is running. Second, you’ll see that the wait4() call is returning two variables called ru_utime and ru_stime. The man page on wait4() clarifies that this return parameter is the rusage struct which is defined in the POSIX spec. The structure is defined in time.h and is the same structure returned by getrusage() and times(). This is how the operating system kernel returns the timing information to “time” for display on the output.
CPU Utilization on Linux with Intel SMT (Hyper-Threading)Since many people are familiar with Linux, it will be helpful to provide a side-by-side comparison of Linux/Intel/Hyper-Threading with AIX/Power7/SMT. This will also help clarify exactly what AIX is doing that’s so unusual.
For this comparison, we will switch to Amos Waterland’s useful stress utility for CPU load generation. This program is readily available for all major unix flavors and cleanly loads a CPU by spinning on the sqrt() function. I found a copy at perzl.org already ported and packaged for AIX on POWER.
For our comparison, we will load a single idle CPU for 100 seconds of wall-clock time. We know that the process will spin on the CPU for all 100 seconds, but lets see how the operating system kernel reports it.
First, lets verify that we have SMT (Hyper-Threading):
user@debian:~$ lscpu | egrep '(per|name)'
Thread(s) per core: 2
Core(s) per socket: 2
Model name: Intel(R) Core(TM) i3-4005U CPU @ 1.70GHz
Next lets run our stress test (pinned to a single CPU) and see what the kernel reports for CPU usage:
user@debian:~$ time -p taskset 2 stress -c 1 -t 100
stress: info: [20875] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd
stress: info: [20875] successful run completed in 100s
real 100.00
user 100.03
sys 0.00
Just what we would expect – the system is idle, and the process was on the CPU for all 100 seconds.
Now lets use mpstat to look at the utilization of CPU #2 in a second window:
user@debian:~$ mpstat -P 1 10 12
Linux 3.16.0-4-amd64 (debian) 06/30/2016 _x86_64_ (4 CPU)
01:58:07 AM CPU %usr %nice %sys %iowait %irq %soft %steal %guest %gnice %idle
01:58:17 AM 1 0.00 0.00 0.10 0.00 0.00 0.00 0.00 0.00 0.00 99.90
01:58:27 AM 1 17.44 0.00 0.10 0.00 0.00 0.00 0.00 0.00 0.00 82.45
01:58:37 AM 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
01:58:47 AM 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
01:58:57 AM 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
01:59:07 AM 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
01:59:17 AM 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
01:59:27 AM 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
01:59:37 AM 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
01:59:47 AM 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
01:59:57 AM 1 100.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
02:00:07 AM 1 82.88 0.00 0.10 0.00 0.00 0.00 0.00 0.00 0.00 17.02
Average: 1 83.52 0.00 0.03 0.00 0.00 0.00 0.00 0.00 0.00 16.45
Again, no surprises here. We see that the CPU was running at 100% for the duration of our stress test.
Next lets check the system-wide view. On linux, most people use with the top command when they want to see what’s happening system-wide. Top shows a list of processes and for each process it estimates how much time is spent on the CPU. top uses the same kernel-tracked POSIX timing data that the time command returns. It then divides by the wall-clock time to express that timing data as a percentage. If two processes are running on one CPU, then each process will report 50% CPU utilization.
We will run top in a third window while the stress and mpstat programs are running to get the system-wide view:

Linux top (in Irix mode) reports that the “stress” program is using 100% of a single CPU and that 26.3% of my total CPU capacity is used by the system.
This is wrong. Did you spot it? If you have any linux servers with hyper-threading enabled then I really hope you understand the problem with this!
The problem is with the second statement – that 26% of my total CPU capacity is used. In reality, a “hardware thread” is nothing like a “real core”. (For more details about Hyper-Threading and CPU Capacity, Karl Arao might be one of the best sources of information.) Linux kernel developers represent each hardware thread as a logical CPU. As a result (and this is counter-intuitive) it’s very misleading to look at that “total CPU utilization” number as something related to total CPU capacity.
What does this mean for you? You must set your CPU monitoring thresholds on Linux/Hyper-Threading very low. You might consider setting critical threshold at 70%. Personally, I like to keep utilization on transactional systems under 50%. If your hyper-threaded linux system seems to have 70% CPU utilization, then in reality you be almost out of CPU capacity!
Why is this important? This is exactly the problem that IBM’s AIX team aimed to solve with SMT on POWER. But there is a catch: the source data used by standard tools to calculate system-level CPU usage is the POSIX-defined “rusage” process accounting information. IBM tweaked the meaning of rusage to fix our system-level CPU reporting problem – and they introduced a new problem at the individual process level. Lets take a look.
CPU Utilization on AIX with Power SMTFirst, as we did on Linux, lets verify that we have SMT (Hyper-Threading):
# prtconf|grep Processor
Processor Type: PowerPC_POWER7
Processor Implementation Mode: POWER 7
Processor Version: PV_7_Compat
Number Of Processors: 4
Processor Clock Speed: 3000 MHz
Model Implementation: Multiple Processor, PCI bus
+ proc0 Processor
+ proc4 Processor
+ proc8 Processor
+ proc12 Processor
# lparstat -i|egrep '(Type|Capacity )'
Type : Shared-SMT-4
Entitled Capacity : 2.00
Minimum Capacity : 2.00
Maximum Capacity : 4.00
So you can see that we’re working with 2 to 4 POWER7 processors in SMT4 mode, which will appear as 8 to 16 logical processors.
Now lets run the exact same stress test, again pinned to a single CPU.
# ps -o THREAD
USER PID PPID TID ST CP PRI SC WCHAN F TT BND COMMAND
jschneid 13238466 28704946 - A 0 60 1 - 240001 pts/0 - -ksh
jschneid 9044322 13238466 - A 3 61 1 - 200001 pts/0 - ps -o THREAD
# bindprocessor 13238466 4
# /usr/bin/time -p ./stress -c 1 -t 100
stress: info: [19398818] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd
stress: info: [19398818] successful run completed in 100s
Real 100.00
User 65.01
System 0.00
Wait… where did my CPU time go?! (This is one of the first things Marcin noticed too!) The AIX kernel reported that my process ran for 100 seconds of wall-clock time, but it was only running on the CPU for 65 seconds of that time!
On unix flavors such as Linux, this means that the operating system was not trying to put the process on the CPU during the missing time. Maybe the process was waiting for a disk operation or a signal from another process. But our stress test only executes the sqrt() function – so we know that it was not waiting for anything.
When you know the process was not waiting, there is only other reason the operating system wouldn’t put the process on the CPU. Look again at our very first demo in this article: two (or more) processes needed to share the CPU. And notice that the user+system time was lower than wall-clock time, exactly like our output here on AIX!
So lets take a look at the system-wide view with the “nmon” utility in a second window. (topas reports CPU usage solaris-style while nmon reports irix-style, so nmon will be more suitable for this test. they are actually the same binary anyway, just invoked differently.)

Wait… this doesn’t seem right! Our “stress” process is the only process running on the system, and we know that it is just spinning CPU with the sqrt() call. The “nmon” tool seems to verify the output of the time command – that the process is only on the CPU for 65% of the time! Why isn’t AIX letting my process run on the CPU?!
Lets take a look at the output of the mpstat command, which we are running in our third window:
# mpstat 10 12|egrep '(cpu|^ 4)'
System configuration: lcpu=16 ent=2.0 mode=Uncapped
cpu min maj mpc int cs ics rq mig lpa sysc us sy wa id pc %ec lcs
4 0 0 0 2 0 0 0 1 100 0 0 49 0 51 0.00 0.0 1
4 19 0 40 143 7 7 1 1 100 19 100 0 0 0 0.61 30.7 7
4 0 0 0 117 2 2 1 1 100 0 100 0 0 0 0.65 32.6 4
4 0 0 0 99 1 1 1 1 100 0 100 0 0 0 0.65 32.6 3
4 0 0 0 107 3 3 1 3 100 0 100 0 0 0 0.65 32.6 6
4 0 0 0 145 5 5 1 3 100 0 100 0 0 0 0.65 32.6 9
4 0 0 0 113 2 2 1 1 100 0 100 0 0 0 0.65 32.6 3
4 0 0 0 115 1 1 1 1 100 0 100 0 0 0 0.65 32.6 7
4 0 0 0 106 1 1 1 1 100 0 100 0 0 0 0.65 32.6 2
4 0 0 0 113 1 1 1 1 100 0 100 0 0 0 0.65 32.6 5
4 0 0 41 152 2 2 1 1 100 0 100 0 0 0 0.65 32.6 3
4 5 0 0 6 0 0 0 1 100 4 100 0 0 0 0.04 1.8 1
Processor 4 is running at 100%. Right away you should realize something is wrong with how we are interpreting the nmon output – because our “stress” process is the only thing running on this processor. The mpstat utility is not using the kernel’s rusage process accounting data and it shows that our process is running on the CPU for the full time.
So… what in the world did IBM do? The answer – which Steve and Marcin published a few years ago – starts with the little mpstat column called “pc”. This stands for “physical consumption”. (It’s called “physc” in sar -P output and in topas/nmon.) This leads us to the heart of IBM’s solution to the system-wide CPU reporting problem.
IBM is thinking about everything in terms of capacity rather than time. The pc number is a fraction that scales down utilization numbers to reflect utilization of the core (physical cpu) rather than the hardware thread (logical cpu). And in doing this, they don’t just divide by four on an SMT-4 chip. The fraction is dynamically computed by the POWER processor hardware in real time and exposed through a new register called PURR. IBM did a lot of testing and then – starting with POWER7 – they built the intelligence in to the POWER processor hardware.
In our example, we are using one SMT hardware thread at 100% in SMT-4 mode. The POWER processor reports through the PURR register that this represents 65% of the processor’s capacity, exposed to us through the pc scale-down factor of 0.65 in mpstat. My POWER7 processor claims it is only 65% busy when one if its four threads is running at 100%.
I also ran the test using two SMT hardware threads at 100% on the same processor in SMT-4 mode. The processor scaled both threads down to 45% so that when you add them together, the processor is claiming that it’s 90% busy – though nmon & topas will show each of the two processes running at only 45% of a CPU! When all four threads are being used at 100% in SMT-4 mode then of course the processor will scale all four processes down to 25% – and the processor will finally show that it is 100% busy.
 On a side note, the %ec column is showing the physical consumption as a percentage of entitled capacity (2 processors). My supposed 65% utilization of a processor equates to 32.6% of my system-wide entitled capacity. Not coincidentally, topas shows the “stress” process running at 32.6% (like I said, solaris-style).
On a side note, the %ec column is showing the physical consumption as a percentage of entitled capacity (2 processors). My supposed 65% utilization of a processor equates to 32.6% of my system-wide entitled capacity. Not coincidentally, topas shows the “stress” process running at 32.6% (like I said, solaris-style).
So AIX is factoring in the PURR ratio when it populates the POSIX rusage process accounting structure. What is the benefit? Topas and other monitoring tools calculate system load by adding up the processor and/or process utilization numbers. By changing the meaning from time to capacity at such a low level, it helps us to very easily get an accurate view of total system utilization – taking into account the real life performance characteristics of SMT.
The big win for us is that on AIX, we can use our normal paging thresholds and we have better visibility into how utilized our system is.
The Big Problem With AIX/POWER7/SMT CPU Accounting ChangesBut there is also a big problem. Even if it’s not a formal standard, it has been a widely accepted convention for decades that the POSIX rusage process accounting numbers represent time. Even on AIX with POWER7/SMT, the “time” command baked into both ksh and bash still uses the old default output format:
# time ./stress -c 1 -t 66
stress: info: [34537674] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd
stress: info: [34537674] successful run completed in 66s
real 1m6.00s
user 0m41.14s
sys 0m0.00s
It’s obvious from the output here that everybody expects the rusage information to describe time. And the real problem is that many software packages use the rusage information based on this assumption. By changing how resource accounting works, IBM has essentially made itself incompatible with all of that code.
Of course, the specific software that’s most relevant to me is the Oracle database.
I did do a basic truss on a dedicated server process; truss logged a call to appgetrusage() which I couldn’t identify but I think it’s most likely calling getrusage() under the hood.
# truss -p 15728860
kread(0, 0x09001000A035EAC8, 1152921504606799456) (sleeping...)
kread(0, 0x09001000A035EAC8, 1152921504606799456) = 207
kwrite(6, "\n * * * 2 0 1 6 - 0 6".., 29) = 29
lseek(6, 0, 1) = 100316
...
kwrite(6, " C L O S E # 4 5 7 3 8".., 59) = 59
kwrite(6, "\n", 1) = 1
appgetrusage(0, 0x0FFFFFFFFFFF89C8) = 0
kwrite(6, " = = = = = = = = = = = =".., 21) = 21
kwrite(6, "\n", 1) = 1
For what it’s worth, I also checked the /usr/bin/time command on AIX – it is using the times() system call, in the same library as getrusage().
# truss time sleep 5
execve("/usr/bin/time", 0x2FF22C48, 0x200130A8) argc: 3
sbrk(0x00000000) = 0x20001C34
vmgetinfo(0x2FF21E10, 7, 16) = 0
...
kwaitpid(0x2FF22B70, -1, 4, 0x00000000, 0x00000000) (sleeping...)
kwaitpid(0x2FF22B70, -1, 4, 0x00000000, 0x00000000) = 26017858
times(0x2FF22B78) = 600548912
kwrite(2, "\n", 1) = 1
kopen("/usr/lib/nls/msg/en_US/time.cat", O_RDONLY) = 3
The fundamental problem for Oracle databases is that it relies on getrusage() for nearly all of its CPU metrics. DB Time and DB CPU in the AWR report… V$SQLSTATS.CPU_TIME… extended sql trace sql execution statistics… as far as I know, all of these rely on the assumption that the POSIX rusage data represents time – and none of them are aware of the physc scaling factor on AIX/POWER7/SMT.
To quickly give an example, here is what I saw in one extended SQL trace file:
FETCH #4578129832:c=13561,e=37669,p=2,cr=527,...
I can’t list all the WAIT lines from this trace file – but the CPU time reported here is significantly lower than the elapsed time after removing all the wait time from it. Typically this would mean we need to check if the CPU is oversaturated or if there is a bug in Oracle’s code. But I suspect that now Oracle is just passing along the rusage information it received from the AIX kernel, assuming that ru_utime and ru_stime are both representing time.
If you use a profiler for analyzing trace files then you might see something like this:

The key is “unaccounted-for time within dbcalls” – this is what I’ve seen associated with the AIX/Power7/SMT change. It’s worth scrolling down to the next section of this profile too:

There was at least a little unaccounted-for time in every single one of the 81,000 dbcalls and it was the FETCH calls that account for 99% of the missing time. The FETCH calls also account for 99% of the CPU time.
What Can We Do NowThe problem with this unaccounted-for time on AIX/SMT is that you have far less visibility than usual into what it means. You can rest assured that CPU time will always be under-counted and a bunch of unaccounted-for time – but there’s no way to guess what the ratio might have been (it could be anywhere from 25% to 75% of the total real CPU time).
I’ve heard one person say that they always double the CPU numbers in the AWR for AIX/SMT systems. It’s a total stab in the dark but perhaps useful to think about. Also, I’m not sure whether someone has opened a bug with Oracle yet – but that should get done. If you’re an Oracle customer on AIX then you should open a ticket now and let Oracle know that you need their code to be aware of SMT resource accounting changes on POWER7!
In the meantime we will just need to keep doing what we can! The most important point to remember is that when you see unaccounted-for time on AIX/SMT, always remember that some or all of this time is normal CPU time which was not correctly accounted.
If you’re running Oracle on AIX, I’d love to hear your feedback. Please feel welcome to leave comments on this article and share your thoughts, additions and corrections!
Patching Time
Just a quick note to point out that the October PSU was just released. The database has a few more vulnerabilities than usual (31), but they are mostly related to Java and the high CVSS score of 9 only applies to people running Oracle on windows. (On other operating systems, the highest score is 6.5.)
I did happen to glance at the announcement on the security blog, and I thought this short blurb was worth repeating:
In today’s Critical Patch Update Advisory, you will see a stronger than previously-used statement about the importance of applying security patches. Even though Oracle has consistently tried to encourage customers to apply Critical Patch Updates on a timely basis and recommended customers remain on actively-supported versions, Oracle continues to receive credible reports of attempts to exploit vulnerabilities for which fixes have been already published by Oracle. In many instances, these fixes were published by Oracle years ago, but their non-application by customers, particularly against Internet-facing systems, results in dangerous exposure for these customers. Keeping up with security releases is a good security practice and good IT governance.
The Oracle Database was first released in a different age than we live in today. Ordering physical parts involved navigating paper catalogs and faxing order sheets to the supplier. Physical inventory management relied heavily on notebooks and clipboards. Mainframes were processing data but manufacturing and supply chain had not yet been revolutionized by technology. Likewise, software base installs and upgrades were shipped on CDs through the mail and installed via physical consoles. The feedback cycle incorporating customer requests into software features took years.
Today, manufacturing is lean and the supply chain is digitized. Inventory is managed with the help of scanners and real-time analytics. Customer communication is more streamlined than ever before and developers respond quickly to the market. Bugs are exploited maliciously as soon as they’re discovered and the software development and delivery process has been optimized for fast response and rapid digital delivery of fixes.
Here’s the puzzle: Cell phones, web browsers and laptop operating systems all get security updates installed frequently. Even the linux OS running on your servers is easy to update with security patches. Oracle is no exception – they have streamlined delivery of database patches through the quarterly PSU program. Why do so many people simply ignore the whole area of Oracle database patches? Are we stuck in the old age of infrequent patching activity even though Oracle themselves have moved on?
RepetitionFor many, it just seems overwhelming to think about patching. And honestly – it is. At first. The key is actually a little counter-intuitive: it’s painful, so you should in fact do it a lot! Believe it or not, it will actually become very easy once you get over the initial hump.
In my experience working at one small org (two dba’s), the key is doing it regularly. Lots of practice. You keep decent notes and setup scripts/tools where it makes sense and then you start to get a lot faster after several times around. By the way, my thinking has been influenced quite a bit here by the devops movement (like Jez Humble’s ’12 berlin talk and John Allspaw’s ’09 velocity talk). I think they have a nice articulation of this basic repetition principle. And it is very relevant to people who have Oracle databases.
So with all that said, happy patching! I know that I’ll be working with these PSUs over the next week or two. I hope that you’ll be working with them too!
Grid/CRS AddNode or runInstaller fails with NullPointerException
Posting this here mostly to archive it, so I can find it later if I ever see this problem again.
Today I was repeatedly getting this error while trying to add a node to a cluster:
(grid)$ $ORACLE_HOME/oui/bin/addNode.sh -silent -noCopy CRS_ADDNODE=true CRS_DHCP_ENABLED=false INVENTORY_LOCATION=/u01/oraInventory ORACLE_HOME=$ORACLE_HOME "CLUSTER_NEW_NODES={new-node}" "CLUSTER_NEW_VIRTUAL_HOSTNAMES={new-node-vip}"
Starting Oracle Universal Installer...
Checking swap space: must be greater than 500 MB. Actual 24575 MB Passed
Oracle Universal Installer, Version 11.2.0.3.0 Production
Copyright (C) 1999, 2011, Oracle. All rights reserved.
Exception java.lang.NullPointerException occurred..
java.lang.NullPointerException
at oracle.sysman.oii.oiic.OiicAddNodeSession.initialize(OiicAddNodeSession.java:524)
at oracle.sysman.oii.oiic.OiicAddNodeSession.<init>(OiicAddNodeSession.java:133)
at oracle.sysman.oii.oiic.OiicSessionWrapper.createNewSession(OiicSessionWrapper.java:884)
at oracle.sysman.oii.oiic.OiicSessionWrapper.<init>(OiicSessionWrapper.java:191)
at oracle.sysman.oii.oiic.OiicInstaller.init(OiicInstaller.java:512)
at oracle.sysman.oii.oiic.OiicInstaller.runInstaller(OiicInstaller.java:968)
at oracle.sysman.oii.oiic.OiicInstaller.main(OiicInstaller.java:906)
SEVERE:Abnormal program termination. An internal error has occured. Please provide the following files to Oracle Support :
"Unknown"
"Unknown"
"Unknown"
There were two notes on MOS related to NullPointerExceptions from runInstaller (which is used behind the scenes for addNode in 11.2.0.3 on which I had this problem). Note 1073878.1 describes addNode failing in 10gR2, and the root cause was that the home containing CRS binaries was not registered in the central inventory. Note 1511859.1 describes attachHome failing, presumably on 11.2.0.1 – and the root cause was file permissions that blocked reading of oraInst.loc.
Based on these two notes, I had a suspicion that my problem had something to do with the inventory. Note that you can get runInstaller options by running “runInstaller -help” and on 11.2.0.3 you can debug with “-debug -logLevel finest” at the end of your addNode command line. The log file is produced in a logs directory under your inventory. However in this case, it produces absolutely nothing helpful at all…
After quite a bit of work (even running strace and ltrace on the runInstaller, which didn’t help one bit)… I finally figured it out:
(grid)$ grep oraInst $ORACLE_HOME/oui/bin/addNode.sh INVPTRLOC=$OHOME/oraInst.loc
The addNode script was hardcoded to look only in the ORACLE_HOME for the oraInst.loc file. It would not read the file from /etc or /var/opt/oracle because of this parameter.
On this particular server, there was not an oraInst.loc file in the grid ORACLE_HOME. Usually the file is there when you do a normal cluster installation. In our case, it’s absence was an artifact of the specific cloning process we use to rapidly provision clusters. As soon as I copied the file from /etc into the grid ORACLE_HOME, the addNode process continued as normal.
Sometimes it would be nice if runInstaller could give more informative error messages or tracing info!
OSP #3a: Build a Standard Cluster Platform
This is the fifth article in a series called Operationally Scalable Practices. The first article gives an introduction and the second article contains a general overview. In short, this series suggests a comprehensive and cogent blueprint to best position organizations and DBAs for growth.
We’ve looked in some depth at the process of defining a standard platform with an eye toward Oracle database use cases. Before moving on, it would be worthwhile to briefly touch on clustering.
Most organizations should hold off as long as possible before bringing clusters into their infrastructure. Clusters introduce a very significant new level of complexity. They will immediately drive some very expensive training and/or hiring demands – in addition to the already-expensive software licenses and maintenance fees. There will also be new development and engineering needed – perhaps even within application code itself – to support running your apps on clusters. In some industries, clusters have been very well marketed and many small-to-medium companies have made premature deployments. (Admittedly, my advice to hold off is partly a reaction to this.)
When Clustering is RightNonetheless there definitely comes a point where clustering is the right move. There are four basic goals that drive cluster adoption:
- Parallel or distributed processing
- Fault tolerance
- Incremental growth
- Pooled resources for better utilization
I want to point out immediately that RAC is just one way of many ways to do clustering. Clustering can be done at many tiers (platform, database, application) and if you define it loosely then even an oracle database can be clustered in a number of ways.
Distributed ProcessingStop for a moment and re-read the list of goals above. If you wanted to design a system to meet these goals, what technology would you use? I already suggested clusters – but that might not have been what came to your mind first. How about grid computing? I once worked with some researchers in Illinois who wrote programs to simulate protein folding and DNS sequencing. They used the Illinois BioGrid – composed of servers and clusters managed independently by three different universities across the state. How about cloud computing? The Obama Campaign in 2008 used EC2 to build their volunteer logistics and coordination platforms to dramatically scale up and down very rapidly on demand. According to the book In Search of Clusters by Gregory Pfister, these four reasons are the main drivers for clustering – but if they also apply to grids and clouds then then what’s the difference? Doesn’t it all accomplish the same thing?
In fact the exact definition of “clustering” can be a little vague and there is a lot of overlap between clouds, grids, clusters – and simple groups of servers with strong & mature standards. In some cases these terms might be more interchangeable than you would expect. Nonetheless there are some general conventions. Here is what I have observed:
Or, alternatively, the term “grid” may more loosely imply a group of servers where nodes/resources and jobs/services can easily be relocated as workload varies. CLOUD New term, implies service-based abstraction, virtualization and automation. It is extremely standardized with a bias toward enforcement through automation rather than policy. Servers are generally single-organization however service consumers are often external. Related to the term “utility computing” or the “as a service” terms (Software/SaaS, Platform/PaaS, Database/DaaS, Infrastructure/IaaS).
Or, alternatively, may (like “grid”) more loosely imply a group of servers where nodes/resources and jobs/services can easily be relocated as workload varies.

Google Trends for Computers and Electronics Category
These days, the distributed processing field is a very exciting place because the technology is advancing rapidly on all fronts. Traditional relational databases are dealing with increasingly massive data volumes, and big data technology combined with pay-as-you-go cloud platforms and mature automation toolkits have given bootstrapped startups unforeseen access to extremely large-scale data processing.
Building for Distributed ProcessingYour business probably does not have big data. But the business case for some level of distributed processing will probably find you eventually. As I pointed out before, the standards and driving principles at very large organizations can benefit your commodity servers right now and eliminate many growing pains down the road.
In the second half of this article I will take a look at how this specifically applies to clustered Oracle databases. But I’m curious, are your server build standards ready for distributed processing? Could they accommodate clustering, grids or clouds? What kinds of standards do you think are most important to be ready for distributed processing?
Chicago Oracle User Community Restart
Chicago is the third largest city in the United States. There are probably more professional Oracle users here than most other areas in the country – and yet for many years now there hasn’t been a cohesive user group.
But right now there’s an opportunity for change. If the professional community of Chicago Oracle users steps up to the plate.
Chicago Oracle User GroupFirst, the Chicago Oracle User Group has just elected a new president. Alfredo Abate is bringing a level of enthusiasm and energy to the position which we’ve been missing for a long time. He’s trying to figure out how to restart the COUG and re-engage the professional community here – but he needs input and assistance from you! If you’re an administrator or developer anywhere near Chicago and you have Oracle software anywhere in your company, then please help Alfredo get the user group going! Here are a few specific things you can do:
- Send Alfredo an email saying congrats and offering suggestions for the COUG. You can find him on LinkedIn or the COUG site below.
- Join the LinkedIn group that Alfredo set up for the COUG.
- Sign up for a free account at the COUG site: chicago.oracle.ioug.org
- Complete the survey at the COUG website (must sign up for free account, then look for “survey” link in the top navigation bar). This will help Alfredo think about planning the next event.
A few years ago, I was part of a group of Oracle database users from different companies in Chicago who started hanging out regularly for lunches downtown. It was never a big event but it was a lot of fun to get together and catch up regularly. However I stopped organizing the lunches after a job change back into travel consulting and the birth of our daughter. I live on the north side of the city, I worked from home when I wasn’t traveling, and I wasn’t able to make trips downtown anymore.
Ever since, I’ve missed hanging out with friends downtown and I’ve always wanted to do these group lunches again. Besides the fact that I really enjoy catching up with people, I think that face-to-face meetups really help strengthen our sense of community as a whole in Chicago.
So – after far too long – I started the lunches again last week.

Oracle DB Lunch Downtown
But it’s improved – there are now lunches happening all over ChicagoLand!
Tomorrow: Deerfield
This wednesday: Des Plaines
Next week wednesday: Downtown
Coming soon: Naperville?
Please join us for a lunch sometime! I promise you’ll find it to be both beneficial and fun! And also, please join the group on meetup.com – then you’ll get reminders about upcoming lunches in Chicago.
Spread the WordEven if you don’t live in Chicago, you can help me out with this – send a brief tweet or quick email to any Oracle professionals you know around Chicago and direct them to this blog post. I hope to see some new life in the Oracle professional community here. It won’t happen by accident.
Command Line Attachment to Oracle Support Service Request
For those who haven’t looked at this in awhile: these days, it’s dirt simple to attach a file to your SR directly from the server command line.
curl –T /path/to/attachment.tgz
–u "your.oracle.support.login@domain.com"
"https://transport.oracle.com/upload/issue/0-0000000000/"
Or to use a proxy server,
curl –T /path/to/attachment.tgz
–u "your.oracle.support.login@domain.com"
"https://transport.oracle.com/upload/issue/0-0000000000/"
-px proxyserver:port
-U proxyuser
There is lots of info on MOS (really old people call it metalink); doc 1547088.2 is a good place to start. There are some other ways to do this too. But really you can skip all that, you just need the single line above!
OEM CLI Commands for Bulk Property Changes
This will be a brief post, mostly so I can save this command somewhere besides the bash_history file on my OEM server. It may prove useful to a few others too… it has been absolutely essential for me on several occasions! (I was just using it again recently which reminded me to stick it in this blog post.) This is how you can make bulk property changes to a large group of targets in OEM:
(oracle)$ emcli login -username=jeremy
(oracle)$ emcli get_targets -noheader -script | sed \
's/Metric Collection Error/MCE/;s/Under Blackout/Blackout/;s/Status Pending/Pending/' >targets
(oracle)$ less targets
(oracle)$ awk '{print$4" "$5" "$6" "$7" "$8"~"$3"~Department~default"}' targets >inp
or... awk '{print$4" "$5" "$6" "$7" "$8"~"$3"~Line of Business~test"}' targets >inp
or... awk '{print$4" "$5" "$6" "$7" "$8"~"$3"~Location~chicago"}' targets >inp
or... awk '{print$4" "$5" "$6" "$7" "$8"~"$3"~LifeCycle Status~Production"}' targets >inp
(oracle)$ less inp
(oracle)$ emcli set_target_property_value -property_records=REC_FILE \
-input_file=REC_FILE:inp -separator=property_records="\n" -subseparator=property_records=~
(oracle)$ emcli logout
Note that the property name is case-sensitive: “Lifecycle” won’t work but “LifeCycle” does. Also, the commands above are of course intended to be tinkered with. Use grep to filter out targets; search on any regular expression you can dream up.
This process is important here because we use Administration Groups to automatically propagate monitoring templates (with standardized metric thresholds for paging) to all of our OEM targets. There have been a number of times when I’ve needed to make bulk property changes and it takes a very long time to do that through the UI. These commands are much faster.
November/December Highlights
In the Oracle technical universe, it seems that the end of the calendar year is always eventful. First there’s OpenWorld: obviously significant for official announcements and insight into Oracle’s strategy. It’s also the week when many top engineers around the world meet up in San Francisco to catch up over beers – justifying hotel and flight expenses by preparing technical presentations of their most interesting and recent problems or projects. UKOUG and DOAG happen shortly after OpenWorld with a similar (but more European) impact – and December seems to mingle the domino effect of tweets and blog posts inspired by the conference social activity with holiday anticipation at work.
I avoided any conference trips this year but I still noticed the usual surge in interesting twitter and blog activity. It seems worthwhile to record a few highlights of the past two months as the year wraps up.
First, four new scripts that look very interesting:
1. Utility: getMOSpatch (doc: blog)- useful script for downloading a specific patch from MOS. I had tried something similar for RACattack back in 2011. This script written by Maris Elsins looks to be very good. I’ve downloaded this and read up on it but haven’t tried it out yet.
2. Perf: ashtop and ash_wait_chains (doc: blog 1, blog 2) – from the author of snapper, here are two more excellent tools for general performance troubleshooting and quickly pulling information from the ASH. The chains script is an especially brilliant idea – it reports from ASH using a hierarchical join on the blocking_session column. Check out Tanel’s blog posts for details and examples. I’ve used both of these scripts while troubleshooting production issues during the past month.
3. Perf/CPU: fulltime (doc: slides) – Linux specific utility to drill down into CPU-intensive processes. Similar to Tanel’s OStackProf but seems a bit more robust (runs server-side without the windows/vbscript dependencies, also brings cpu/kernel together with wait info in a single report). Rather than oradebug, this uses new lightweight linux kernel instrumentation (perf) to report a sample-based profile of what the Oracle kernel is doing by internal function. This was a collaborative effort by Craig Shallahamer and Frits Hoogland and there are several related articles on both blogs about how it works. I’ve downloaded this but haven’t tried it out yet.
4. Perf/Visualization: [Ora/Py] LatencyMap (doc: blog/sqlplus, blog/python) – very cool looking program which gives a heatmap visual representation of metrics such as I/O. I’m a huge fan of visualizations and use graphical tools daily as a DBA. Make sure to check out the recorded demo of this utility!
I love exploring utilities like these. It brings out my nerdy side a little, that’s why I mentioned them first… :) But there are a few other highlights that come to mind from the past few months too!
On the topic of utilities, I have been working with Tanel’s “tpt” script collection quite a bit during the course of my day-to-day job. I fired out a question this month to the oracle-l mailing list about other publicly posted script collections, and I got the impression that there just aren’t many script collections posted publicly! Here’s the list I came up with:
Script Collections:
– Tanel Poder (tpt), see also E2SN for even more
– Tim Hall (oracle-base)
– Dan Morgan
– Kerry Osborne (2010 Hotsos Presentation), see also various blog articles for many updated scripts
– Tim Gorman
– Jeff Hunter
I’ve also read lots of other interesting stuff this month. Three things I remember off the top of my head:
– In 2012, Yury Velikanov wrote up a presentation about oracle database backups. Last month, Maris Elsins made a few tweaks and delivered the updated presentation at UKOUG. The slide deck is a worthwhile read – everybody should be able to learn something from it. If you didn’t see it when Yury first released it last year then take a few minutes to check it out.
– I was interested to read Kellyn Pot’Vin‘s slides about Database as a Service (DBaaS). This is an area I’ve been working on a lot lately and it intersects with my Operationally Scalable Practices series of articles. She’s always got good content about OEM on her blog too – being a heavy OEM user these days, I tend to read what Kellyn’s writing.
– Kyle Hailey recorded Christo Kytrovsky‘s excellent OakTable World talk about Oracle, Memory and Linux. Worth listening to sometime.
You may already be aware but I have to mention that RAC Attack has hit the accelerator lately! Through an international collaborative effort, the curriculum was updated to version 12c of the database before OpenWorld 2013 and this was followed by a rapid series of workshops. During the past three months, there have been four workshops in three different countries – and there are more coming on the calendar!
Finally, two quick “news” type mentions. First, I’ve personally tryed to avoid much of the “engineered systems” buzz (not sure why)… but I did notice the new exadata release this month. Second, oracle made an acquisition this year which was particularly significantly to me: a chicago-based company called BigMachines. You may not have heard of this company – but it happens to be mentioned on my LinkedIn profile.
These are a handful of interesting things I remember seeing over the past two months. Please leave me a comment and mention anything else that you noticed recently – I’m very interested to hear any additional highlights!
Readable Code for Modify_Snapshot_Settings
It annoyed me slightly that when I googled modify_snapshot_settings just now and all of the examples used huge numbers for the retention with (at best) a brief comment saying what the number meant. Here is a better example with slightly more readable code. Hope a few people down the road cut-and-paste from this article instead and the world gets a few more lines of readable code as a result. :)
On a side note, let me re-iterate the importance of increasing the AWR retention defaults. There are a few opinions about the perfect settings but everyone agrees that the defaults are a “lowest common denominator” suitable for demos on laptops but never for production servers. The values below are what I’m currently using.
BEGIN
DBMS_WORKLOAD_REPOSITORY.modify_snapshot_settings(
retention => 105 * 24 * 60, -- days * hr/day * min/hr (result is in minutes)
interval => 15); -- minutes
END;
/
SQL> select * from dba_hist_wr_control;
Pivoting output using Tom Kyte's printtab....
==============================
DBID : 3943732569
SNAP_INTERVAL : +00000 00:15:00.0
RETENTION : +00105 00:00:00.0
TOPNSQL : DEFAULT
PL/SQL procedure successfully completed.
Elapsed: 00:00:00.10
Largest Tables Including Indexes and LOBs
Just a quick code snippit. I do a lot of data pumps to move schemas between different databases; for example taking a copy of a schema to an internal database to try to reproduce a problem. Some of these schemas have some very large tables. The large tables aren’t always needed to research a particular problem.
Here’s a quick bit of SQL to list the 20 largest tables by total size – including space used by indexes and LOBs. A quick search on google didn’t reveal anything similar so I just wrote something up myself. I’m pretty sure this is somewhat efficient; if there’s a better way to do it then let me know! I’m posting here so I can reference it in the future. :)
with segment_rollup as (
select owner, table_name, owner segment_owner, table_name segment_name from dba_tables
union all
select table_owner, table_name, owner segment_owner, index_name segment_name from dba_indexes
union all
select owner, table_name, owner segment_owner, segment_name from dba_lobs
union all
select owner, table_name, owner segment_owner, index_name segment_name from dba_lobs
), ranked_tables as (
select rank() over (order by sum(blocks) desc) rank, sum(blocks) blocks, r.owner, r.table_name
from segment_rollup r, dba_segments s
where s.owner=r.segment_owner and s.segment_name=r.segment_name
and r.owner=upper('&schema_name')
group by r.owner, r.table_name
)
select rank, round(blocks*8/1024) mb, table_name
from ranked_tables
where rank<=20;
The output looks like this:
Enter value for schema_name: someschema
RANK MB TABLE_NAME
---------- ---------- ------------------------------
1 14095 REALLYBIGTABLE_USESLOBS
2 6695 VERYBIG_MORELOBS
3 5762 VERYLARGE
4 5547 BIGBIG_LOTSOFINDEXES
5 446 MORE_REASONABLE
6 412 REASONABLE_TABLE_2
7 377 ANOTHERONE
8 296 TABLE1235
9 280 ANOTHER_MADEUP_NAME
10 141 I_CANT_POST_PROD_NAMES_HERE
11 99 SMALLERTABLE
12 92 NICESIZETABLE
13 89 ILIKETHISTABLE
14 62 DATATABLE
15 53 NODATATABLE
16 48 NOSQLTABLE
17 30 HERES_ANOTHER_TABLE
18 28 TINYTABLE
19 24 ACTUALLY_THERES_400_MORE_TABLES
20 19 GLAD_I_DIDNT_LIST_THEM_ALL
20 rows selected.
And just a quick reminder – the syntax to exclude a table from a data pump schema export is:
expdp ... exclude=SCHEMA_EXPORT/TABLE:[TABNAME],[TABNAME],...
Hope this is useful!
OSP #2c: Build a Standard Platform from the Bottom-Up
This is the fourth of twelve articles in a series called Operationally Scalable Practices. The first article gives an introduction and the second article contains a general overview. In short, this series suggests a comprehensive and cogent blueprint to best position organizations and DBAs for growth.
This article – building a standard platform – has been broken into three parts. We’ve already discussed standardization in general and looked in-depth at storage. Now it’s time to look in-depth at three more key decisions: CPU and memory and networking.
ConsolidationOne of the key ideas of Operationally Scalable Practices is to start early with standards that don’t get in the way of consolidation. As you grow, consolidation will be increasingly important – saving both money and time. Before we dig into specifics of standardizing CPU and memory, we need to briefly discuss consolidation in general.
Consolidation can happen at many levels:
- Single schema and multiple customers
- Single database and multiple schemas or tenants (12c CDB)
- Single OS and multiple databases
- Single hardware and multiple OS’s (virtualization)
Two important points about this list. First, it works a lot like performance tuning: the biggest wins are always highest in the stack. If you want to save time and money then you should push to consolidate as high as possible, ideally in the application. But there are often forces pushing consolidation lower in the stack as well. For example:
- Google doesn’t spin up new VMs every time a new customer signs up for Google Apps. Their existing webapp stack handles new customers. This is a great model – but if your app wasn’t designed this way from the beginning, it could require a massive development effort to add it.
- It’s obvious but worth stating: you can only push consolidation up a homogenous stack. If the DB runs on linux and the app runs on windows then naturally they’ll each need their own VM. Same goes for the other three tiers.
- Server operating systems have robust multiuser capabilities – but sharing an Operating System can still be tricky and these days virtualization offers a strong value proposition (especially when combined with automation). Then there are containers, which fall somewhere in between single OS and virtualization.
- Security or regulatory or contractual requirements may require separate storage, separate databases or separate operating systems.
- A requirement for independent failover may drive separate databases. In data guard, whole databases (or whole container databases) must be failed over as a single unit.
The second important point is that realistically you will encounter all four levels of consolidation at some point as you grow. Great standards accommodate them all.
CPUIn my opinion, batch workloads can vary but interactive workloads should always be CPU-bound (not I/O-bound). To put it another way: there are times when your database is mainly servicing some app where end-users are clicking around. At those times, your “top activity” graph in enterprise manager should primarily be green. Not blue, not red, not any other color. (And not too much of that green!) I’m not talking about reports, backups, or scheduled jobs – just the interactive application itself. (Ideally you even have some way to distinguish between different categories of activity, in which case there are ways to look at the profile of the interactive traffic even when there is other activity in the database!)
This leads into the question of how much CPU you need. I don’t have any hard and fast rules for CPU minimums in a standard configuration. Just two important thoughts:
- Maximum unit of consolidation: CPU is a major factor in how many applications can be consolidated on a single server. (Assuming that we’re talking about interactive applications with effective DB caching – these should be primarily CPU-bound.)
- Minimum unit of licensing: If partitioning or encryption becomes a requirement for you six months down the road then you’ll have to license the number of cores in one server. Oracle requires you to license all CPUs physically present in the server if any feature is used on that server.
The goal is to limit future purchasing to this configuration. And as with storage, if you really must have more than one configuration, then try to keep it down to two (like a high-CPU option).
MemoryI don’t have a formula to tell you how much memory you should standardize on either. It’s surprising how often SGAs are still poorly sized today – both too small and too large. You need to understand your own applications and their behavior. It’s worthwhile to spend some time reading sar or AWR reports and looking at historical activity graphs.
Once you start to get a rough idea what your typical workload looks like, I would simply suggest to round up as you make the final decision on standard total server memory capacity. There are two reasons for this:
- OS and database consolidation have higher memory requirements. Application and schema/multitenant consolidation will not be as demanding on memory – but as we pointed out earlier, your standards should support all levels of consolidation.
- You’re probably not maxing out the memory capacity of your server and it’s probably not that expensive to bump it up a little bit.
Small companies generally start with one network. But these days, networking can quickly get complicated even at small companies since network gear allows you to define and deploy multiple logical networks on the physical equipment. Early on, even if it doesn’t all seem relevant yet, I would recommend discussing these networking topics:
- Current traffic: Are you gathering data on current network usage? Do you know how much bandwidth is used by various services, and how bursty those services are?
- Logical segregation: Which network should be used for application traffic? What about monitoring traffic, backup traffic, replication traffic (e.g. data guard or goldengate) and operations traffic (kickstarts, data copies between environments, etc)? What about I/O traffic (e.g. NFS or iSCSI)? What is the growth strategy and how will this likely evolve over the coming years?
- Physical connections: How many connections do we need, accounting for redundancy and isolation/performance requirements and any necessary physical network separation?
- Clustering: Clustering generally require a dedicated private network and tons of IPs (on both the private cluster network and your corporate network). Sometimes it has higher bandwidth and latency requirements than usual. Generally it is recommended to deploy RAC on at least 10G ethernet for the interconnect. Is there a general strategy for how this will be addressed when the need arises?
It will benefit you greatly to take these discussions into consideration early and account for growth as you build your standard platform.
SlotsOne design pattern that I’ve found to be helpful is the idea of slots. The basic idea is similar to physical PCI or DIMM slots – but these are logical “slots” which databases or VMs can use. This is a simplified, practical version of the service catalog concept borrowed from ITIL for private cloud architectures – and this can provide a strong basis if you grow or migrate to that point.
- Determine the smallest amount of memory which a standardized database (SGA) or VM will use. This will determine a slot size.
- Determine the largest amount of memory which can be allocated on the server. For databases, about 70% of server memory for SGA is a good starting point if it’s an interactive system. For VMs it’s possible to even allow more memory than is physically present but I don’t know the latest conventional wisdom about doing this.
- Choose additional DB or VM size options as even multiples of the minimum size.
For example, a database server containing 64GB of memory might have a slot size of 5GB with 9 total available slots. Anyone who wants a database can choose either a small or large database; a small database uses 1 slot and its SGA is 5GB. A large database uses 5 slots and its SGA is 25GB.
After the basic slot definition has been decided, CPU limits can be drafted. If the database server has 8 physical cores then the small database might have a hard limit of 2 CPUs and a large database might have a hard limit of 6 CPUs.
One area which can be confusing with CPU limits is factoring in processor threads. When determining your limits for a consolidation environment, make sure that individual applications are capped before pushing the total load over the physical number of CPUs. But allow the aggregate workload to approach the logical number of CPUs in a period of general heavy load coming from lots of applications.
In practice, that means:
- For multiple databases, set cpu_limit on each one low according to the physical count and calibrate the aggregate total against the logical count.
- For multiple schemas in a single database: use resource manager to limit CPU for each schema according to physical count and set cpu_count high according to logical count.
Now you have a first draft of memory and CPU definitions for a small and large database. The next step is to define the application workload limits for each database size. As you’re consolidating applications into a few databases, how many instances of your app can be allowed in a small and large database respectively?
Suppose you’re a SAAS company who hosts and manages lots of SAP databases for small businesses. I don’t actually know what the CPU or memory requirements of SAP are so I’m making these numbers up – but you might decide that a small database (5GB/2cpu) can support one SAP instance and a large database (25GB/6cpu) can support 25 instances (with PDBs).
Remember that schema/multi-tenant consolidation is very efficient – so you can service many more applications with less memory compared to multiple databases. For a starting point, make sure that the large database uses more than half of the slots then use server CPU capacity to determine how many app instances can be serviced by a large database.
Another observation is that your production system probably uses more CPU than your test and dev systems. You may be able to double or triple the app instance limits for non-production servers.
It’s an iterative process to find the right slot sizes and workload limits. But the payoff is huge: something that’s easy to draw on a whiteboard and explain to stakeholders. Your management has some concrete figures to work with when projecting hardware needs against potential growth. The bottom line is that you have flexible yet strong standards – which will enable rapid growth while easing management.
Example Slot Definitions Database Size Slots Max SAP Instances (Production Server) Max SAP Instances (Test Server) Small 1 1 2 Large 5 25 50Standard Server: - 8 Cores - 64 GB Memory - 9 Slots nr_hugepages = 23552 (45 GB plus 1 GB extra)
Standard Database: sga_target/max_size = [slots * 5] GB pga_aggregate_target = [slots * 2] GB cpu_count = [slots + 1] processes = [slots * 400]