
Jan Kettenis
Jan Kettenishttp://www.blogger.com/profile/14146264706360751350noreply@blogger.comBlogger151125
Updated: 17 hours 39 min ago
OIC: Making a REST Integration Returning a 404 instead of 500
In this article I describe how to return a HTTP 404 (resource) Not Found with a REST integration that on its turn calls another REST service that returns a 404.
This article is superseded by my article Fault Handling in OIC, which gives you the proper way to do this.
When an integration invokes the GET action on a REST service that returns a 404, the integration will raise an APIInvocationError. As a result, the integration on its turn will respond with a HTTP 500 error, which is typically not what you want.
Embedding the invoke in a Scope gives you the option to add a Fault Handler:

Chosing the APIInvocationError gives you the option to configure how any APIInvocationError should be handled. As you can see below, I have configured it to use a Switch, where the top flow will make it return a 404:

In all honesty this is not watertight, because I filter on all APIInvocationErrors where the type is empty (“”). The reason being that all the elements, type, title, detail and errorCode are empty, so I cannot filter on anything.

As I found out, you will also run into this situation when the URL of the Connection used for the invoke is wrong, and probably a few other situations as well. I rely on the assumption that my integration is properly configured, so that the most likely cause of an APIInvocationError indeed is that it concerns a 404.
To make my integration return a 404, I map this as a hard-coded value to the errorCode:

Except for the errorCode I have hard-coded the other elements as well. Probably not exactly according to the specifications, but good and especially clear enough for me:

In the meantime, in the background there is a SOAP fault with a reason containing the HTTP 404, so at some point I hope this will be exposed so that I can filter in a reliable way:

OIC: Handling Optional Elements in a REST Integration
This article is a follow-up of the a previous article where I discuss how to handle optional elements in case of XML in the Oracle Integration Cloud (OIC). In the following I discuss how to create an integration that invokes VBCS REST service and works in (almost) the same way as the VBCS REST service itself.
A challenge with mapping is always how to handle optional elements. In the previous posting that I refer to above, I describe a way how to deal with this in case of XML messages. As I found out (the hard way) this is cannot be applied 100% to JSON.
I have made it work for an integration that invokes the REST service on a VBCS business object. As there are challenges especially with numeric fields and references (foreign keys), I have used a simple BO called Detail having a string field, a number field and a reference. With VBCS BO’s the latter implies a number field that references the (number) id field of another BO it refers to, which in this case is called Master.
The Master BO looks as follows (ignore the create/update fields, those are generated by default and for the example not relevant):

The Detail BO looks as follows:

As you can see, name (string), master (reference to Master.id, number) and age (number) are all optional.
I created a single REST integration that, using the OIC Pick Action feature has a POST, GET and PATCH action to create, get and update a Detail:

Use if-function for Mapping InputExcept for the PATCH action, all mappings to the requests of the invoke use the if-function to check if the source has a value, and only if it has maps it to the target:

Use string-length() for Mapping OutputThe mappings from the invokes to the response of the integration all use the string-length() function to check if the response element of the invoke has a value, and if so maps it to the target.

I make use of the fact that internally JSON is transformed into XML and there is no payload validation, so numbers also can be checked using string-length(). By doing it like this the element will be left out completely, instead of being returned as an empty string “” or failing in case of a number. This is not 100% as the VBCS service works (which will return null instead of leaving the field out), but for me that is not an issue when using the integration.
Special Case: PATCHIn case of a PATCH I need my integration working so that left-out elements are not updated (i.e. stay untouched) and that I can nullify them by passing null as a value. For the invoke to the VBCS REST service this will fail for number elements (with JSON a number is a primitive type that cannot be null). I therefore apply a trick by using a JSON sample payload that treats all elements as string, including the master and age (both number):
{"name": "Huey", "master": "1", "age": "15"}
This, in combination with the if-function when mapping the request to the PATCH invoke, makes it work the same way as the VBCS REST service works. For the response I use the string-length() as described above.
The picture on the left side shows an example of an invoke to the PATCH action with all elements present, and on the right side where all elements are nullified:


As you can see, nullifying the master results in a reference to a row with Master.id = 2, which happens to be the only Master row with no name. The VBCS REST service works the same way, so apparently some ‘intelligence’ is applied here. When adding an extra Master with no name so that now I have two of those, VBCS can no longer decide which one to take and nullifies the reference to the master altogether:

When I leave out any element in the request, the field in the BO is not touched. It’s a bit boring to see, so I will spare you the screenshots. You will have to trust me on that.
A challenge with mapping is always how to handle optional elements. In the previous posting that I refer to above, I describe a way how to deal with this in case of XML messages. As I found out (the hard way) this is cannot be applied 100% to JSON.
I have made it work for an integration that invokes the REST service on a VBCS business object. As there are challenges especially with numeric fields and references (foreign keys), I have used a simple BO called Detail having a string field, a number field and a reference. With VBCS BO’s the latter implies a number field that references the (number) id field of another BO it refers to, which in this case is called Master.
The Master BO looks as follows (ignore the create/update fields, those are generated by default and for the example not relevant):

The Detail BO looks as follows:

As you can see, name (string), master (reference to Master.id, number) and age (number) are all optional.
I created a single REST integration that, using the OIC Pick Action feature has a POST, GET and PATCH action to create, get and update a Detail:

Use if-function for Mapping InputExcept for the PATCH action, all mappings to the requests of the invoke use the if-function to check if the source has a value, and only if it has maps it to the target:

Use string-length() for Mapping OutputThe mappings from the invokes to the response of the integration all use the string-length() function to check if the response element of the invoke has a value, and if so maps it to the target.

I make use of the fact that internally JSON is transformed into XML and there is no payload validation, so numbers also can be checked using string-length(). By doing it like this the element will be left out completely, instead of being returned as an empty string “” or failing in case of a number. This is not 100% as the VBCS service works (which will return null instead of leaving the field out), but for me that is not an issue when using the integration.
Special Case: PATCHIn case of a PATCH I need my integration working so that left-out elements are not updated (i.e. stay untouched) and that I can nullify them by passing null as a value. For the invoke to the VBCS REST service this will fail for number elements (with JSON a number is a primitive type that cannot be null). I therefore apply a trick by using a JSON sample payload that treats all elements as string, including the master and age (both number):
{"name": "Huey", "master": "1", "age": "15"}
This, in combination with the if-function when mapping the request to the PATCH invoke, makes it work the same way as the VBCS REST service works. For the response I use the string-length() as described above.
The picture on the left side shows an example of an invoke to the PATCH action with all elements present, and on the right side where all elements are nullified:


As you can see, nullifying the master results in a reference to a row with Master.id = 2, which happens to be the only Master row with no name. The VBCS REST service works the same way, so apparently some ‘intelligence’ is applied here. When adding an extra Master with no name so that now I have two of those, VBCS can no longer decide which one to take and nullifies the reference to the master altogether:

When I leave out any element in the request, the field in the BO is not touched. It’s a bit boring to see, so I will spare you the screenshots. You will have to trust me on that.
The Fault Encapsulation Pattern
This posting discusses an integration pattern where you return a fault as a message instead of as a fault, to prevent that the execution of the integration is indicated as having errored.
There are a couple of situations where you may not want a synchronous integration to return a fault to its consumer. Examples are:
- Some back-end system is raising a fault which is not really a fault but a way to give the consumer a particular outcome. Like a credit limit check that returns OK when the limit is not reached, but otherwise gives a CreditLimitReached fault.
- A call to the back-end system may time out, telling the integration that the system is not available, which may be a regular state. For example, the integration calls the system to check if it is still running, and if it is tell it to shut down. When the system is already shut down the call will time out.
The reason you may not want to return a fault to the consumer of your integration, at least not as a fault, might be that this flags the execution of the integration to be errored. For example, integrations in the Oracle Integration Cloud (OIC) will show up in the Dashboard as errored instances. That on its turn should trigger Systems Administration to have a look why it failed, only to find out it did not as that is normal behavior. Before you know it, Systems Administration stops having a look, also when there is something seriously wrong with your integration.
To prevent this from happening you may want to handle the fault as an alternate flow instead of an exception flow. This is what the Fault Encapsulation pattern is about.
Fault Encapsulation PatternIn simple terms, when applying the Fault Encapsulation pattern, you don't return an error for business faults, but instead encapsulate the error in a "message" element of the response which is an optional part of the normal response.
The following "BPEL-ish" diagram shows how this looks.

The invoke to the back-end system is a scope with a catch block that catches the error, wraps it in a normal message and then returns the response. In OIC this works in a similar way.
More formally:
Context:
A business fault in a synchronous service operation should not stop its processing, to allow returning other information than the fault alone.
A business fault caught by a synchronous service operation that otherwise executed properly, should not flag the operation as failed to prevent false positive error notifications. Instead handling of the fault should be part of normal process execution by the consumer.
Solution:
The fault in the synchronous service operation is caught using an exception handler that wraps the fault in a message element. The message element is an optional part of the regular response message of the synchronous service operation. System faults in the processing of the synchronous service operation itself are handled as regular faults, in case of SOAP by raising a SOAP Fault, or in case of REST by returning a 4xx or 5xx HTTP status code.
Implication:
The consumer cannot use any regular fault handling mechanisms to handle the business fault. Instead it will have to check for the message element being present in the response and act on that.
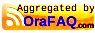
Oracle Integration Cloud: How to Rename or Delete a Swimlane Role
In the category "it was right in front of me, but I was too blind to see" below how you can "rename" and delete a swimlane (application) role. The documentation Work with Process Roles and Swimlanes for example does not discuss this, and Googling it did not help me either. So here you go...
Deleting a swim-lane is easy, you select it and press Delete or the delete icon at the top.
However, this does not delete the role itself. The issue is that when you activate the application, it will turn up in the Workspace (Administration -> Manage Roles). You can delete it there but with the next activation it is back again.
The way to do it is by going to the small icon on the top-right corner (just above the "hamburger menu") which reveals the "General Properties". There below is the link to "Organization", which takes you to a pop-up where you can delete the role


Make sure you don't use it anywhere before deleting. Otherwise the swimlane will change to "Unassigned role" which will not result in a validation error, can be activated, resulting in an application role in Workspace with name "Unassigned role". Then you have to delete that in two places (Composer and Workspace).

You cannot rename a role. For example when I want to rename the role with name "Role With Tipo" into "Role Without Typo" I have to add the latter and then delete the first.
Deleting a swim-lane is easy, you select it and press Delete or the delete icon at the top.

However, this does not delete the role itself. The issue is that when you activate the application, it will turn up in the Workspace (Administration -> Manage Roles). You can delete it there but with the next activation it is back again.
The way to do it is by going to the small icon on the top-right corner (just above the "hamburger menu") which reveals the "General Properties". There below is the link to "Organization", which takes you to a pop-up where you can delete the role


Make sure you don't use it anywhere before deleting. Otherwise the swimlane will change to "Unassigned role" which will not result in a validation error, can be activated, resulting in an application role in Workspace with name "Unassigned role". Then you have to delete that in two places (Composer and Workspace).

You cannot rename a role. For example when I want to rename the role with name "Role With Tipo" into "Role Without Typo" I have to add the latter and then delete the first.
Oracle Dynamic Process Calling Structured Process Caveat
When implementing a Dynamic Process, there currently are three options to implement a case activity: Human Task, Service (or Integration), and Process. At least up to version 18.4.5.0.0 there is limitation when defining the interface in case of a Process Activity making that you cannot use a Business Type which is based on an XSD element, which on its turn in based on a complexType. The below describes the problem you will run into, and a suggestion of how to work-around this.
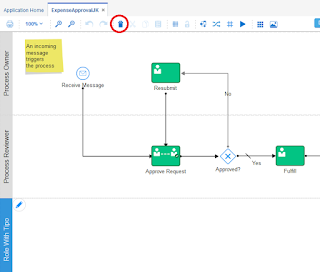
When developing XSD's for web services you may have developed the practice of defining a complexType with an element based on that complexType, for example as in the below XSD.
Reason could be that you developed with the (on-premise) SOA or BPM Suite and found this to give the best flexibility, especially when integrating with Oracle Business Rules.
However, when you base the input argument of a Structured Process on an element that on its turn is based on a complex type, you will find this does not work when using it to implement the input argument of a Process Activity. You will run in to an error similar to the following:

In the example below the "First" activity is implemented as a Process activity with name "SRElementStart".

The Dynamic Process has a start argument based on the Business Type "RequestElement" that is created using the "request" element from the XSD:


Also the Structured Process has a start argument based on "RequestElement":

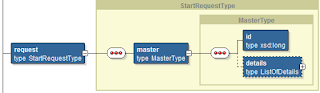
For the Process activity with name "First" the process input argument is mapped to the input argument of the Structured Process:
When running this application it fails in the Start event of the Structured Process with the error mentioned at the beginning.
The problem being that when invoking the Structured Process, the Dynamic Process uses the name of the Business Type instead of the name of the argument to invoke it.
The solution is to define the input argument using a Business Type that is based on the complexType (instead of the element).
So far this is the only place where I ran into this issue. After fixing it I can map the of the Structured Process input argument backed by the complexType to a (local) Business Object backed by the element without an issue. I can also map the same Business Object back to the Dynamic Process Business Object (backed by the element) without an issue. Business Object backed by an element can be mapped 1:1 on a Business Object backed by a complexType.
You can prevent the issue by defining all your Business Types on complexTypes, or only for the input argument of Structured Processes. So far I have not found any limitations to do the first, so that probably is the easiest to do.
Many thanks to Luc Gorissen who helped my to discover the solution, and let's hope that with some next version this restriction is gone.
When developing XSD's for web services you may have developed the practice of defining a complexType with an element based on that complexType, for example as in the below XSD.

Reason could be that you developed with the (on-premise) SOA or BPM Suite and found this to give the best flexibility, especially when integrating with Oracle Business Rules.
However, when you base the input argument of a Structured Process on an element that on its turn is based on a complex type, you will find this does not work when using it to implement the input argument of a Process Activity. You will run in to an error similar to the following:

In the example below the "First" activity is implemented as a Process activity with name "SRElementStart".

The Dynamic Process has a start argument based on the Business Type "RequestElement" that is created using the "request" element from the XSD:


Also the Structured Process has a start argument based on "RequestElement":

For the Process activity with name "First" the process input argument is mapped to the input argument of the Structured Process:

When running this application it fails in the Start event of the Structured Process with the error mentioned at the beginning.
The problem being that when invoking the Structured Process, the Dynamic Process uses the name of the Business Type instead of the name of the argument to invoke it.
The solution is to define the input argument using a Business Type that is based on the complexType (instead of the element).
So far this is the only place where I ran into this issue. After fixing it I can map the of the Structured Process input argument backed by the complexType to a (local) Business Object backed by the element without an issue. I can also map the same Business Object back to the Dynamic Process Business Object (backed by the element) without an issue. Business Object backed by an element can be mapped 1:1 on a Business Object backed by a complexType.
You can prevent the issue by defining all your Business Types on complexTypes, or only for the input argument of Structured Processes. So far I have not found any limitations to do the first, so that probably is the easiest to do.
Many thanks to Luc Gorissen who helped my to discover the solution, and let's hope that with some next version this restriction is gone.
Understanding Mapping Optional Elements in OIC Integration
There are some easy to make mistakes to make when mapping messages with optional elements in OIC Integrations. This article describes how optional elements are being handled, and a way to make this work the way you want.
OIC Integration handles optional elements the same for both XML as well as JSON based elements, including mapping from XML to JSON and vise verse. The reason being that internally OIC will map JSON to XML. The examples hereafter therefore are based on XML.
I will discuss the examples on the following XSD that is used in an integration that maps all elements 1:1 and echoes the result back.

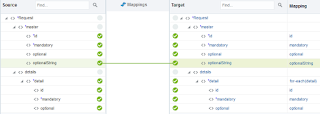
"Optional" in this context means that the element can be completely left out using 'minOccurs="0"'. Apart from that one can also specify if a null value can be assigned to the element using 'nillable="true"'. This means that an empty tag is allowed in the message (e.g. <optional/> or <optional></optional>).
When only the mandatory elements of the master are passed on you will find that all optional elements are echoed as empty, even those of the child:

The first mistake you could have made is to expect all elements that are not provided with the request not to be in the response either. Not a strange assumption considering that in XML Schema the default for the nillable attribute is "false", so strictly speaking, according to the XSD the response is not valid XML.
The reason OIC handles it like this is one of fault tolerance as in case of a 1:1 mapping where the source is not present, the alternative would be giving a selectionFailure (the equivalence of a NullPonterException).
Although appreciating this fault-tolerant way of mapping for ease of use for more 'Citizen Developer' type of users, it might not be what you want. It will specifically result in challenges when you are dealing with external systems that rely on the conceptual difference between an element that is left out to mean: "we don't know the value", versus empty to mean: "we know there is no value" (e.g. it may not be applicable in the context of usage). Another reason for leaving empty elements out of the message may be to keep the size of the message as small as possible.
There is a first step to work-around this, which is making use of if-function (coming from XSLT / XPath which is the technology used under the hood) for all optional elements:
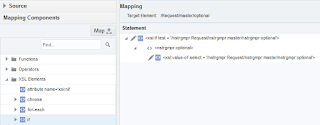
With the echo service this results in the following:
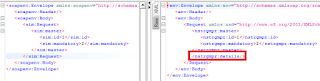
You now my have ran into the second mistake (I did) as although none of the optional root elements are present, the root element <details/> still is. This can be resolved by also using the if-function for that element:
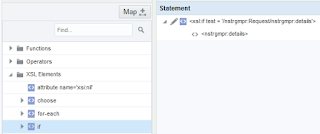
There still may be a challenge to overcome. You may have a similar issue in OIC Processes that, unlike with OIC Integrations, currently does not have the possibility to conditionally map elements, and leave empty elements out. So when you call an Integration from OIC you also may have to deal with empty elements as well. For that you can use a trick where the if-function is used in combination with the string-length(). Using this function on empty elements will result in "false" what also works for number elements (as these will automatically be converted to string). In the following both have been applied on the master.optional element:
You can read this as: if the element is present, then if it has a string length (meaning it is or could be converted to a string, so it is not empty), then map its value.
Some next time I will blog about a new feature to come in OIC Process to handle conditional mappings.
OIC Integration handles optional elements the same for both XML as well as JSON based elements, including mapping from XML to JSON and vise verse. The reason being that internally OIC will map JSON to XML. The examples hereafter therefore are based on XML.
I will discuss the examples on the following XSD that is used in an integration that maps all elements 1:1 and echoes the result back.


"Optional" in this context means that the element can be completely left out using 'minOccurs="0"'. Apart from that one can also specify if a null value can be assigned to the element using 'nillable="true"'. This means that an empty tag is allowed in the message (e.g. <optional/> or <optional></optional>).
When only the mandatory elements of the master are passed on you will find that all optional elements are echoed as empty, even those of the child:

The first mistake you could have made is to expect all elements that are not provided with the request not to be in the response either. Not a strange assumption considering that in XML Schema the default for the nillable attribute is "false", so strictly speaking, according to the XSD the response is not valid XML.
The reason OIC handles it like this is one of fault tolerance as in case of a 1:1 mapping where the source is not present, the alternative would be giving a selectionFailure (the equivalence of a NullPonterException).
Although appreciating this fault-tolerant way of mapping for ease of use for more 'Citizen Developer' type of users, it might not be what you want. It will specifically result in challenges when you are dealing with external systems that rely on the conceptual difference between an element that is left out to mean: "we don't know the value", versus empty to mean: "we know there is no value" (e.g. it may not be applicable in the context of usage). Another reason for leaving empty elements out of the message may be to keep the size of the message as small as possible.
There is a first step to work-around this, which is making use of if-function (coming from XSLT / XPath which is the technology used under the hood) for all optional elements:

With the echo service this results in the following:

You now my have ran into the second mistake (I did) as although none of the optional root elements are present, the root element <details/> still is. This can be resolved by also using the if-function for that element:

There still may be a challenge to overcome. You may have a similar issue in OIC Processes that, unlike with OIC Integrations, currently does not have the possibility to conditionally map elements, and leave empty elements out. So when you call an Integration from OIC you also may have to deal with empty elements as well. For that you can use a trick where the if-function is used in combination with the string-length(). Using this function on empty elements will result in "false" what also works for number elements (as these will automatically be converted to string). In the following both have been applied on the master.optional element:
You can read this as: if the element is present, then if it has a string length (meaning it is or could be converted to a string, so it is not empty), then map its value.
Some next time I will blog about a new feature to come in OIC Process to handle conditional mappings.
Dynamic Process, Conditions and Scope
In Oracle Integration Cloud's Dynamic Processes activation/termination conditions can be based on case events. These events are related to the scope of the components they relate to, which implies some restrictions. The below explains how this works, and how to work around these restrictions.
A Dynamic Process or Case (as I will call it in this article) in the Oracle Integration Cloud consists of four component types: the Case itself, Stages (phases), Activities, and Milestones. An Activity or Milestone is either in a particular Stage (in the picture below Activities A to H are), or global (Activities X and Y). Cases, Processes, Stages, Activities and Miletones cannot be nested (but a Case can initiate a sub-Case via an Activity, which I will discuss another time).

Except for the case itself, all other components can explicitly be activated/enabled or terminated/completed based on conditions. For example in the dynamic process above Milestone 1 is activated once Activity A is completed, and Stage 2 is to be activated once Stage 1 is completed.
A Stage implicitly completes when all work in that stage is done (i.e. all Activities), and a Case implicitly completes when all work in the case is done. Currently the status of a Case cannot be explicitly set using conditions, but I would expect this to become possible in some next version. In the meantime there is a REST API that can be used to close or complete a case.
There are two types of conditions for explicit activation/termination:
- (case) Events, for example completion of an activity
- (case) Data Driven, for example "status" field gets value "started"
The scope of an Event is its container, meaning:
- A Stage can only be activated or terminated by a condition based on an Event concerning another Stage or a Global Activity.
- An Activity can only be activated or terminated by a condition based on an Event concerning another Activity or Milestone in the same Stage.
- A Milestone can only be completed by a condition based on an Event concerning an Activity or another Milestone in the same Stage.
- A Global Activity can only be enabled or terminated by a condition based on an Event concerning a Stage, or Global Milestone or another Global Activity
- A Global Milestone can only be enabled or terminated by a condition based on an Event concerning a Stage, a Global Activity, or another Global Milestone
Let's assume that in the example Stage 2 is only to be activated when Milestone 1 is completed and otherwise Stage 2 is to be skipped and the case should directly go to Stage 3. Because of the way events are limited by their scope, you cannot create a condition for Stage 2 to be skipped based on the completion of Milestone 1 (which is in Stage 1 and therefore not visible outside).
The work-around is to use a Data Driven condition instead. You can for example have a "metaData.status" field that you can set to something like "skip phase 2" and use that instead.
In general, it probably always is a good idea to let your case have some complex data element for example called "metaData" consisting of fields like "dateStarted" and "status", which that you fill out via the activities, and if needed can be used in conditions everywhere.
Oracle Integration Cloud: New! The Data Mapper Activity
In a previous blog I discussed a work-around for not having a Script activity in Oracle Integration Cloud's Process Builder. In this blog I will discuss another work-around which is actually not a work-around, but the real thing: the Data Mapper!
As you can read in a previous blog about the matter, not having the equivalent of the Script activity of the on-premise BPM Suite, was an omission that we often had to find a work-around for. The one I used was the Business Rule activity. However, some weeks ago the Business Rule activity got deprecated (you could clearly see that).

With the latest release of OIC (which may not yet be public available when you read this) the Business Rule activity has vanished. At the same time the Data Mapper activity has been added.

The Data Mapper activity has no properties other than that you can put it in draft mode.

The implementation is as simple as you might expect: there is only an Output tab on which you can map data from Data Objects, Predefined Variables and Business Parameters on one hand, to Data Objects and Predefined Variables on the other.

Next to simple mappings, you can also create and use (reusable) transformations to map Data Objects (or attributes) of which the types don't match.

I hope I don't have to write this any time in the future again, but if you used my work-around I got you into trouble if you want to export and import an application, because import with a Business Rule activity in the application is not supported! Sorry :-D
As you can read in a previous blog about the matter, not having the equivalent of the Script activity of the on-premise BPM Suite, was an omission that we often had to find a work-around for. The one I used was the Business Rule activity. However, some weeks ago the Business Rule activity got deprecated (you could clearly see that).
With the latest release of OIC (which may not yet be public available when you read this) the Business Rule activity has vanished. At the same time the Data Mapper activity has been added.

The Data Mapper activity has no properties other than that you can put it in draft mode.

The implementation is as simple as you might expect: there is only an Output tab on which you can map data from Data Objects, Predefined Variables and Business Parameters on one hand, to Data Objects and Predefined Variables on the other.

Next to simple mappings, you can also create and use (reusable) transformations to map Data Objects (or attributes) of which the types don't match.

I hope I don't have to write this any time in the future again, but if you used my work-around I got you into trouble if you want to export and import an application, because import with a Business Rule activity in the application is not supported! Sorry :-D
Oracle Integration Cloud: Customer Managed & Patching
Currently the Oracle Integration Cloud (OIC) only comes as "customer managed". Among others this means that you as a customer have access to management consoles. It also means that you determine when to apply patches, as Oracle does not do that for you. The following describes how easy that is.
Oracle Cloud solutions can come in two flavors: Oracle Managed and Customer Managed. The first means that maintenance, including patching is done by Oracle. You don't have to ask for nor to initiate it as it all happens "automatically", typically during non-business hours (like Friday evening). It also means that you don't have any control over it. Now that probably is exactly what you want. However, in case of OIC that currently only comes as Customer Managed. This means that you have access to the Weblogic Service Console and the Fusion Middleware Console (although not with all the features that you for example would have with the on-premise version of the BPM Suite). I expect these consoles not to be available in the Oracle Managed flavor to come soon.
Another difference will be the way it is provisioned. With the Customer Managed flavor you have to provision a Storage Cloud yourself, and - depending on the type of template you use - also the Database Cloud.
With Oracle Managed I expect this to happen in one blow but that is yet to be seen. With Customer Managed you also have to think about how to configure the Stack that you want to use. A Stack is based on a Stack Template, which specifies the amount of nodes, OCPU's, memory, database version and edition of a node (and a few other things). A Stack is a provisioned instance of a template. After provisioning you cannot change the instance or use another template. However you can provision more instances based on the same stack. Another thing to point out is that with the Customer Managed flavor you need to indicate if and how you want it to be backed up.
Apart from some complexity but also flexibility that comes with determining your Stack Template, after provisioning there is little difference with the Oracle managed flavor. You can use it the same way, and if you have it configured to automatically do backups you don't have to think about that either. You do have to keep a keen eye on patches that may have become available, though.
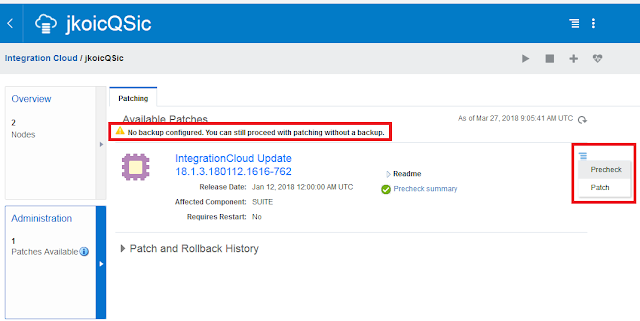
If a patch is available, that will be shown on the Service Console:

You can start patching by clicking the link, which brings you to the Patch tab. In my case this gives a warning that I have no backup configured. It is a trial-only instance so I did not bother to do so. For a Production instance you should have done that (obviously). I don't know if I can still change that for my instance, but I don't think so. On the right-hand side there is a menu with two options: Precheck and Patch.
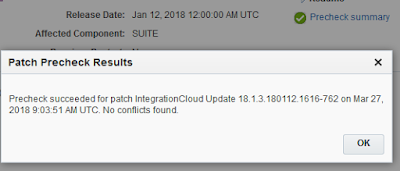
With the Precheck option you can let OIC verify if your instance is ready to apply the patch to. In my case it is.
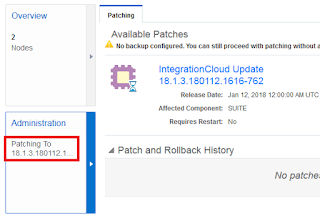
With the Patch option from the menu you initiate the actual patching. In my case the patch can be done rolling what means with the instance up-and-running. As a matter of fact, the patch cannot be applied with one or more instances being shut down.

There also was a patch for the DB instance available, which required a restart. I could only apply that after shutting down the OIC instance, but that is indicated clearly.
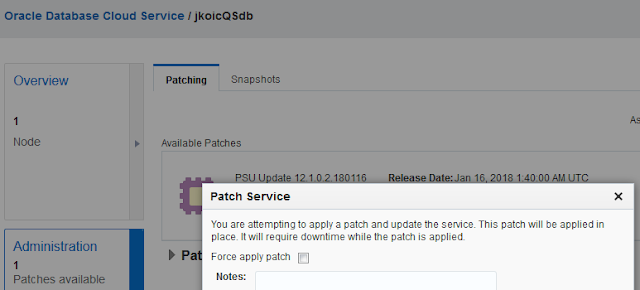
Just for the fun of it I did the precheck of the patch after applying it. It failed, what I expected because it was already applied. The results were not very clear though.

Oracle Cloud solutions can come in two flavors: Oracle Managed and Customer Managed. The first means that maintenance, including patching is done by Oracle. You don't have to ask for nor to initiate it as it all happens "automatically", typically during non-business hours (like Friday evening). It also means that you don't have any control over it. Now that probably is exactly what you want. However, in case of OIC that currently only comes as Customer Managed. This means that you have access to the Weblogic Service Console and the Fusion Middleware Console (although not with all the features that you for example would have with the on-premise version of the BPM Suite). I expect these consoles not to be available in the Oracle Managed flavor to come soon.

Another difference will be the way it is provisioned. With the Customer Managed flavor you have to provision a Storage Cloud yourself, and - depending on the type of template you use - also the Database Cloud.
With Oracle Managed I expect this to happen in one blow but that is yet to be seen. With Customer Managed you also have to think about how to configure the Stack that you want to use. A Stack is based on a Stack Template, which specifies the amount of nodes, OCPU's, memory, database version and edition of a node (and a few other things). A Stack is a provisioned instance of a template. After provisioning you cannot change the instance or use another template. However you can provision more instances based on the same stack. Another thing to point out is that with the Customer Managed flavor you need to indicate if and how you want it to be backed up.
Apart from some complexity but also flexibility that comes with determining your Stack Template, after provisioning there is little difference with the Oracle managed flavor. You can use it the same way, and if you have it configured to automatically do backups you don't have to think about that either. You do have to keep a keen eye on patches that may have become available, though.
If a patch is available, that will be shown on the Service Console:

You can start patching by clicking the link, which brings you to the Patch tab. In my case this gives a warning that I have no backup configured. It is a trial-only instance so I did not bother to do so. For a Production instance you should have done that (obviously). I don't know if I can still change that for my instance, but I don't think so. On the right-hand side there is a menu with two options: Precheck and Patch.

With the Precheck option you can let OIC verify if your instance is ready to apply the patch to. In my case it is.

With the Patch option from the menu you initiate the actual patching. In my case the patch can be done rolling what means with the instance up-and-running. As a matter of fact, the patch cannot be applied with one or more instances being shut down.



Just for the fun of it I did the precheck of the patch after applying it. It failed, what I expected because it was already applied. The results were not very clear though.

Oracle Integration Cloud Tips & Trics: Work-around for no Script Activity
Oracle Process Cloud Services (PCS) nor the Process Builder in Oracle Integration Cloud (OIC) have a Script activity like there is in (on-premise) BPM Suite. In the BPM Suite you can use a Script activity for data mappings as well as Groovy. That OIC does not support Groovy is by design as the idea is to keep it as simple as possible. However missing the data mapping feature of the Script activity can make it even more complex than ever. Fortunately there is some data mapping activity on the road-map of some next version of OIC. Until then you can make use of the work-around below.
There can be several reasons why you may want to have an activity just for mapping data, among them:
A such the Rule activity is deprecated as it is superseded by the Decision activity, but as long as it is there (and a Mapping activity is not) we can make good use of it.
Below an example. This concerns some Process that is being used in a Dynamic Process application, to set up some case meta data. The case meta data is stored and checked for duplicates. The Store Meta Data activity is in draft mode because I'm developing it iteratively. One of the elements of the meta data is a startDate, which I want to set to the creationDate predefined variable.
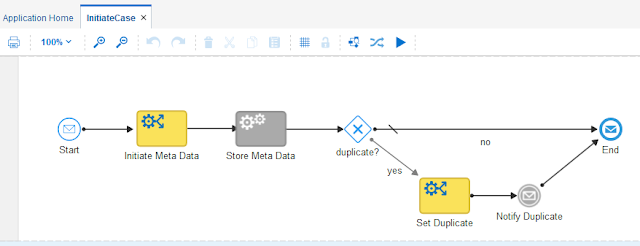
I cannot do the mapping to the startDate in the Start event, because there it is not available. But even if it was, for reasons of clarity I would like to have it clearly visible in the process model.

I therefore created a Rule activity with uses an input and output argument, both of the MetaData business type.

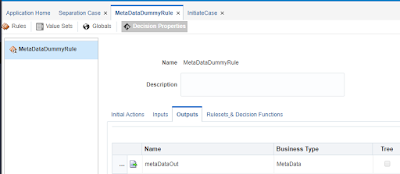
I can do all mappings on the Input and Output Data Association tabs, so I do not actually have to implement a rule. The result will be that the input is mapped to the output 1:1. But for more complex use cases you can actually implement rules as well.


The run-time result is as shown in the next picture.

There can be several reasons why you may want to have an activity just for mapping data, among them:
- Readability of the process model, making it clear which data is set where in the process.
- Data mapping is conditional, making it too complex or impossible to do it in the Input or Output mapping of (for example) a Service activity.
- A conditional mapping before a Gateway.
- Iterative development, requiring (temporary) "hard-coding".
A such the Rule activity is deprecated as it is superseded by the Decision activity, but as long as it is there (and a Mapping activity is not) we can make good use of it.
Below an example. This concerns some Process that is being used in a Dynamic Process application, to set up some case meta data. The case meta data is stored and checked for duplicates. The Store Meta Data activity is in draft mode because I'm developing it iteratively. One of the elements of the meta data is a startDate, which I want to set to the creationDate predefined variable.

I cannot do the mapping to the startDate in the Start event, because there it is not available. But even if it was, for reasons of clarity I would like to have it clearly visible in the process model.

I therefore created a Rule activity with uses an input and output argument, both of the MetaData business type.

I can do all mappings on the Input and Output Data Association tabs, so I do not actually have to implement a rule. The result will be that the input is mapped to the output 1:1. But for more complex use cases you can actually implement rules as well.


The run-time result is as shown in the next picture.

What Makes MicroServices Different from SOA?
In this article I will discuss what is different between MicroServices and a traditional Service Oriented Architecture as such an architecture may look looks like when you know for example Oracle SOA. I also discuss some of misconceptions heard or read concerning MicroServices. It is written by and for a person that knows SOA and is wonders what to do with MicroServices. If MicroServices is what you do already, I probably have little news for you.
I wrote this article many months ago, but somehow forgot to publish.
What's Different Compared to Traditional SOA?In his article on InfoWorld Matt McLarty states that this question should not matter. The real question is: "what we can learn from the SOA movement", and I concur with his 5 important lessons. Nevertheless, even after reading his article, people like me will keep on wondering what the practical implications may be on the way we use our technology now and how we should change that.
All in all most of the MicroServices principles are fundamental to what I would consider to be a "good" Service Oriented Architecture. Of course, there is no such thing as the SOA, although in my opinion many best practices, and lessons learned the hard way, have lead to identifying some generic characteristics of the more successful ones, which in the below I refer to as classical SOA.
The way I see it (from my classical SOA perspective):
Statefull vs StatelessMicroServices are stateless by principle. In SOA it is a best practice to avoid stateful services but that is not a principle. You should try to avoid stateful BPEL, but when creating a composite service that involves one or more asynchronous services, that leaves you little choice. As I explain in my previous blog about MicroServices and BPM and Case Management, the latter two are stateful by definition, so there you also don't have a choice.
Multiple vs Single Containers
I wrote this article many months ago, but somehow forgot to publish.
What's Different Compared to Traditional SOA?In his article on InfoWorld Matt McLarty states that this question should not matter. The real question is: "what we can learn from the SOA movement", and I concur with his 5 important lessons. Nevertheless, even after reading his article, people like me will keep on wondering what the practical implications may be on the way we use our technology now and how we should change that.
All in all most of the MicroServices principles are fundamental to what I would consider to be a "good" Service Oriented Architecture. Of course, there is no such thing as the SOA, although in my opinion many best practices, and lessons learned the hard way, have lead to identifying some generic characteristics of the more successful ones, which in the below I refer to as classical SOA.
The way I see it (from my classical SOA perspective):
Statefull vs StatelessMicroServices are stateless by principle. In SOA it is a best practice to avoid stateful services but that is not a principle. You should try to avoid stateful BPEL, but when creating a composite service that involves one or more asynchronous services, that leaves you little choice. As I explain in my previous blog about MicroServices and BPM and Case Management, the latter two are stateful by definition, so there you also don't have a choice.
However, in case of aynchronous (request/response) communication, some next time you may consider using events instead, where the response is not handled by an asynchronous callback but by publishing an event by means of the EDN or using JMS). Generally this complicates the implementation, but who said that MicroServices did not come with a price?
Reuse
SOA is about reuse. In a classical SOA there often are a number of small, reusable "technical" services that are then reused to compose bigger "business services". Examples include some service to handle asynchronous interaction in a generic way, and a service that retrieves some list of values from a database. We made them to speed up the development process, because creating the next application takes less time by reusing the services we created for the previous one.
Everybody happy, until a new requirement makes we have to change the generic service with potential impact on all existing applications using it. If you are lucky some regression test suite is available to verify that the existing functionality keeps on working, but even then you may find that people don't feel comfortable unless all the other applications have been retested as well. You then may come to a point where you start wondering if all that reuse was such a great idea.
Much more than classical SOA, MicroServices are about minimal function services build around business capabilities (not necessarily 'fine-grained'), where reuse is even discouraged if that introduces dependencies that may jeopardize business agility. There obviously is reuse with MicroServices (a reusable printing service provides a sensible business capability), but you should for example avoid shared custom Java libraries that are deployed independently. Also in a classical SOA you can avoid this by making sure that you package a specific version of the library with the service so that it will never be impacted by any change unless you want it to.
In general, compared to classical SOA, applying MicroServices principles will make you start thinking differently about the responsibility, and granularity of services. Again, this may come with a price as some functionality may have to be duplicated to support business agility.
Data Services vs Data Replication
In general, compared to classical SOA, applying MicroServices principles will make you start thinking differently about the responsibility, and granularity of services. Again, this may come with a price as some functionality may have to be duplicated to support business agility.
Data Services vs Data Replication
In a classical SOA we may not think for a second before deciding we need a (reusable) data service to get customer data. When reading about MicroServices you will find that the (already classical) example of a bad practice is having some sort of a CustomerDataService that may fail, and with that result in the failure of an OrderService to complete successfully.
It is for this reason that the Design for Failure principle implies that a MicroService should have its own data store when possible, and may have its own copy of shared business data like customer data. In this way the successful completion of the OrderService is never dependent on some CustomerDataService to be available. Data is synchronized when necessary and feasible.
You may already have realized that this is a specialization of the reuse issue addressed in the previous section. You will also realize that this is one of the more, if not most complex challenges to address, and the choice to replicate data is not be an easy decision to make.
HTTP vs RESTThe interface of MicroServices should be simple, which almost de facto seems to imply REST (over HTTP) and JSON. With classical SOA this typically is SOAP and XML, although by no means you are limited to that. For a while already we start seeing more and more SOA services with REST interfaces.
With classical SOA many services will be deployed on the same SOA container, all sharing the same infrastructure (data sources, messaging, Operations tooling, etc.) that the container provides. Reuse of that infrastructure being the reason to do so.
However, as a result, one single service behaving badly can impact all other services on the same container. I have seen cases where a single failing service brought down the complete container. One of the reasons to deploy every version of a MicroService in its own container is to prevent this type of issues. In this way it can be scaled, improved, and fixed without affecting any other MicroService.
However, as a result, one single service behaving badly can impact all other services on the same container. I have seen cases where a single failing service brought down the complete container. One of the reasons to deploy every version of a MicroService in its own container is to prevent this type of issues. In this way it can be scaled, improved, and fixed without affecting any other MicroService.
ChoreographyAs I explain in my previous posting about MicroServices, there can be quite a few challenges to overcome when business functionality has to be supported by a set of MicroServices working together. Quite a few of those you could be avoided or addressed much more easily when all services would be deployed on the same container (which in a classical SOA is more or less the default), in particular related to monitoring and Operations.
If there is any area in which MicroServices could quickly start adding value to a classical SOA, then it is by orchestrating MicroServices (instead of classical SOA services) in case of Business Process Management or Case Management. Compared to classical SOA, what you will get "for free" is that the cluttering of the orchestration by technical aspects will be kept to the minimum (if existing at all) as you will be orchestrating business functions with (mostly) business-oriented interfaces.
Technology Choices
If there is any area in which MicroServices could quickly start adding value to a classical SOA, then it is by orchestrating MicroServices (instead of classical SOA services) in case of Business Process Management or Case Management. Compared to classical SOA, what you will get "for free" is that the cluttering of the orchestration by technical aspects will be kept to the minimum (if existing at all) as you will be orchestrating business functions with (mostly) business-oriented interfaces.
Technology Choices
With classical SOA the technology is limited to what the SOA container supports. For example, in case of Oracle you primarily implement your services using BPEL, Mediator or BPMN, simply because that is the easiest to do. Of course there can be good arguments for restricting the technologies used (even in a MicroServices environment you might want to have guidelines on that) but in practice you may find that this does not always result in the best designed, constructed, and operating service. If all you have is a hammer...
In contrast, MicroServices are polyglot regarding technology, where for each individual MicroService you will use the technology that is best suited considering the functionality you have to provide and the skills present in the team. Different types of MicroServices may have a complete different way of implementation, and using a complete different set of technologies. However, except for the interface, the technology used is completely transparent for the consumer.
Message TransformationAnother MicroServices principle is smart endpoints / dumb pipes, meaning that there is no transformation or enrichment happening in some Enterprise Service Bus. If an ESB is used then that is limited to routing and perhaps as a layer for enforcing security. In a classical SOA architecture transformation and some types of enrichment is typically done in the Service Bus.
- DevOps implies MicroServices. It's more the other way around. DevOps is about culture and shared responsibility for the operation of one application. That can also be applied to many other architectures.
- SOA is not MicroServices. Many see MicroServices is a sub-domain of SOA. As James Lewis and Martin Fowler state, some consider MicroServices as SOA done right.
- There is no use for a Enterprise Service Bus in a MicroService architecture. Well, you may still need the routing and security features it can offer (see also the section Message Transformation above). Perhaps not the traditional Enterprise Service Bus as we know it, but more something that you could call a "Business Event Bus".
Oracle BPM: Time for Time Out (2)
In a previous blog posting I discussed a solution to re-initiate a scope in BPMN that is supposed to time out after some time. In this posting I discuss how that solution inspires a couple of other use cases where a time out has to be re-initiated by calling an operation on the process.
In the following process model there are three flow, for three different use cases to re-initiate the time-out of:

Re-initiate Timer for Process InstanceThe trick here is to use an Event Based gateway that either fires when the time-out occurs, or responds to the call to the re-initiation operation (Reinitiate Requested in the picture) which passes on a new duration. The Timeout Event Gateway is started again, whereby the the new duration is used to (re)schedule the Time Out timer. The reinitiate Gateway is necessary to loop back, and is the default. The condition of the no flow is "false".
The following picture shows the flow when that happens.

Re-initiate Timer for Receive ActivityThe re-initiation of the Receive activity happens through a Boundary Message event. The dummy Gateway does not do anything but is necessary to loop back to. The Receive is then rescheduled with a timer that has a new duration as passed on through the call.
The following picture shows the flow when that happens.

Re-initiate Timer for a User ActivityIn the previous two examples, the timer is completely (re)scheduled with the passed-on duration. In the bottom example the time-out of the User activity happens by setting the expiration on the Human Task. This is the recommended way as it will make the expiration visible in Workspace, and make sure the Human Workflow Engine properly cleans up the Human Task (which was not always the case in previous releases of the Oracle BPM Suite).
What happens in this scenario is that the expiry is actually not re-initiated but instead paused for a while using an Update activity with operation "Suspend Timers", then wait, and then continue the timer using an Update activity with operation "Resume Timers". This construction allows usage of an (non-interrupting) Event Subprocess, which has the advantage that it does not clutter the rest of the process model, you keep the same Human Task instance (with the same taskId) plus, if you have multiple Human Tasks at the same time, you can also use this construction to suspend other user activities as well.


The following picture shows the flow when that happens.

If you want to re-initiate the timer in a similar way as in the previous two use cases, then you can use the second solution with a Boundary Timer event and a Boundary Message event. The result will be that the Human Task is actually aborted (as said not in some older 11g versions), and then a new instance is created (with a new taskId!). Depending on your process model you can also put the User activity in a scope of its own, and re-initiate the timer of that as described in the previous posting on this topic.
In the following process model there are three flow, for three different use cases to re-initiate the time-out of:
- A process instance (top flow),
- An (asynchronous) Receive activity (middle flow),
- A User activity (bottom flow).

Re-initiate Timer for Process InstanceThe trick here is to use an Event Based gateway that either fires when the time-out occurs, or responds to the call to the re-initiation operation (Reinitiate Requested in the picture) which passes on a new duration. The Timeout Event Gateway is started again, whereby the the new duration is used to (re)schedule the Time Out timer. The reinitiate Gateway is necessary to loop back, and is the default. The condition of the no flow is "false".
The following picture shows the flow when that happens.

Re-initiate Timer for Receive ActivityThe re-initiation of the Receive activity happens through a Boundary Message event. The dummy Gateway does not do anything but is necessary to loop back to. The Receive is then rescheduled with a timer that has a new duration as passed on through the call.
The following picture shows the flow when that happens.

Re-initiate Timer for a User ActivityIn the previous two examples, the timer is completely (re)scheduled with the passed-on duration. In the bottom example the time-out of the User activity happens by setting the expiration on the Human Task. This is the recommended way as it will make the expiration visible in Workspace, and make sure the Human Workflow Engine properly cleans up the Human Task (which was not always the case in previous releases of the Oracle BPM Suite).
What happens in this scenario is that the expiry is actually not re-initiated but instead paused for a while using an Update activity with operation "Suspend Timers", then wait, and then continue the timer using an Update activity with operation "Resume Timers". This construction allows usage of an (non-interrupting) Event Subprocess, which has the advantage that it does not clutter the rest of the process model, you keep the same Human Task instance (with the same taskId) plus, if you have multiple Human Tasks at the same time, you can also use this construction to suspend other user activities as well.


The following picture shows the flow when that happens.

If you want to re-initiate the timer in a similar way as in the previous two use cases, then you can use the second solution with a Boundary Timer event and a Boundary Message event. The result will be that the Human Task is actually aborted (as said not in some older 11g versions), and then a new instance is created (with a new taskId!). Depending on your process model you can also put the User activity in a scope of its own, and re-initiate the timer of that as described in the previous posting on this topic.
Oracle Weblogic: Tackling Class Loading Issues for SOA Infra
This blog article discusses how to address class loading issues with the Oracle SOA Infra. It's prime "raison d'etre" being a memory dump of something I don't do often, but may spend significant time in finding out how to do it again.
Some time ago I lost valuable time because some library being deployed twice, once in the wrong place ([SOA_HOME]/lib folder) and once in the right place ([SOA_HOME]/soa/modules/oracle.soa.ext_11.1.1). In this particular case the first was wrong because the library was using classes that were only loaded when the SOA infrastructure was initialized.
I had created a composite that relied upon some code from the jar, which I knew should be there, but every time it was called it gave me a NoSuchMethodError. A nasty problem because deployment of the jar file was not done by me, but instead by some Operations department that I could only contact indirectly, and any request could easily take a day to get resolved. Of course I blamed these stupid people from Operations that did not even know how to deploy a jar file properly, and undoubtedly Operations was blaming this idiot calling himself a developer but did not know how to code straight. Polite as we both are, we did not say so to each other of course. Me giving you this anecdote only to point out one of disadvantages of not doing DevOps ;-)
But then came the WebLogic Classloader Analysis Tool (or CAT for short) to the rescue. With that I was able to determine that my jar was loaded from both the lib folder as well as the oracle.soa_ext_11.1.1 but as the first one has preference over the seconds one, my composite always went to the old lib, even though Operations did deploy the latest version to the proper location, So somewhere early in the process Operations did deploy it in the wrong location (ha!), but then again at the time I probably did not give them proper instructions about its location either (hmm...).
There already is enough information to be found about the Classloader Analysis Tool, including this one, so I just will stick to explaining how I found out to find out what is being loaded from the lib folder of the SOA Server and what from the oracle.soa_ext_11.1.1 folder.
To go to CAT use a URL like this; http://[server]:[port]/wls-cat. Make sure you go to the SOA Server, and not the Admin Server (unless that is one and the same). Any class loaded by the SOA infra you can find from soa-infra -> soa-infra -> View: detailed -> Classloader Tree. The jars from the lib folder are loaded by the java.net.URLClassLoader whereas the SOA infra itself (including the external jars) are loaded by the weblogic.utils.classloaders.GenericClassLoader.

Oracle BPM: Time for Time Out
In this posting I describe how to time out a specific BPM scope with the option to re-initiate the timer.
In case you need to model a time out for a specific scope within a process where you want to be able to modify the time out run-time, then you can model it similar to this:

A parallel flow is used where the top flow covers the main process, and the bottom flow handles the timeout. To make the timeout configurable, the bottom flow uses an Event Gateway with a Message event to interrupt the timer and re-initiate it again. The first of the two flows that reaches the Complex Merge aborts the other one (first come, first served), as configured in the Complex Merge:

Note: If you want re-initiation to happen based on a Signal, than you cannot use that in an Event Gateway. However, as a work-around you can define a separate component in the composite that is subscribed to the Signal event, and then calls the "Reinitiation Requested" Message Start event.
Time Out FlowThe timer is configured using an expression that results in a duration:

Furthermore you need some variable that is initiated in the Start operation as false, e.g. called a "mainProcessTimesOut":

"mainProcessTimeOut" is set to true in the "Set Timed Out" Script activity, and used in the "timed out?" Exclusive Gateway to go to the "End" or "Timed Out" End event.
Reinitiate FlowThe "Reinitiation Requested" Message Catch event exposes a "reinitiateTimer" operation that takes the new expiry duration as input, plus an id to correlate the instance:

As the "Reinitiation Requested" Message Catch is only activated in case re-initialization of the timer is requested, the condition of the no-flow from "reinitiate?" can simply be set to false, and the yes-flow as the default.
In case you need to model a time out for a specific scope within a process where you want to be able to modify the time out run-time, then you can model it similar to this:

A parallel flow is used where the top flow covers the main process, and the bottom flow handles the timeout. To make the timeout configurable, the bottom flow uses an Event Gateway with a Message event to interrupt the timer and re-initiate it again. The first of the two flows that reaches the Complex Merge aborts the other one (first come, first served), as configured in the Complex Merge:

Note: If you want re-initiation to happen based on a Signal, than you cannot use that in an Event Gateway. However, as a work-around you can define a separate component in the composite that is subscribed to the Signal event, and then calls the "Reinitiation Requested" Message Start event.
Time Out FlowThe timer is configured using an expression that results in a duration:

Furthermore you need some variable that is initiated in the Start operation as false, e.g. called a "mainProcessTimesOut":

"mainProcessTimeOut" is set to true in the "Set Timed Out" Script activity, and used in the "timed out?" Exclusive Gateway to go to the "End" or "Timed Out" End event.
Reinitiate FlowThe "Reinitiation Requested" Message Catch event exposes a "reinitiateTimer" operation that takes the new expiry duration as input, plus an id to correlate the instance:

As the "Reinitiation Requested" Message Catch is only activated in case re-initialization of the timer is requested, the condition of the no-flow from "reinitiate?" can simply be set to false, and the yes-flow as the default.
Oracle BPM: Hiding Faults from BPM? Don't use Service Activity!
In the following I explain how you can hide faults from BPM by not using (synchronous) Service activities, but (asynchronous) Send/Receive activities instead.


Now lets refactor this to a solution where the Service Layer will hide the fault from the BPM process. To do so, all calls from the BPM process to the Service Layer will have to be asynchronous.


When calling services from a BPM process, you should think about where you want faults to show up and to be handled. This is specifically of interest when you have some integration layer between your BPM processes and external services that you call to abstract the external services from the BPM process. Let's call this layer the Service Layer. I have seen such a layer in various formats, ranging from a Reusable Subprocess, a BPEL process in the same composite as the BPM process, or a BPEL process in a separate composite, or instead of BPEL a Mediator. You may have such a layer to hide technical details from the business process, to cover some sort of custom exception handling, or to hide the message format from these external services from the BPM process (or a combination of all that). The latter might be because you don't have the luxury to do message transformation in a service bus.
In case the BPM process calls the Service Layer through a (synchronous) Service activity and that fails, then this will result in the main BPM instance to get into an errored state, and you will have to handle the error in the BPM process. This behavior might be exactly what you wanted to prevent with the Service Layer, for example because the Service call is in a parallel flow and you want to be sure that the fault does not impact processing of the other, parallel threads.
The following example shows what happens. It concerns a main BPM process, that calls synchronous ServicePS from the Service Layer, which on its turn calls some other ServiceA that (finally) calls a FailingService that always fails. The example is a bit over complicated because I configured a fault policy in the synchronous services. You may be aware that I wrote some other article explaining that this is not a good practice, but when creating this example I did not had that insight yet ;-) So bear with me and just ignore these synchronous services still being in a "Running" state after they failed.
The following shows the synchronous BPEL of the ServicePS.

Because the whole chains of calls is synchronous from beginning to the end, you will see that all synchronous services have the "Faulted" state. Because of the fault policy in the BPM (the only one that makes sense in this case) it is still running, but because the fault bubbled up to the BPM instance that shows the error as well.

Because the whole chains of calls is synchronous from beginning to the end, you will see that all synchronous services have the "Faulted" state. Because of the fault policy in the BPM (the only one that makes sense in this case) it is still running, but because the fault bubbled up to the BPM instance that shows the error as well.


The following shows the asynchronous BPEL of ServiceAsyncPS_NP.

Learning from my earlier mistake with the fault policy, this asynchronous service now is the only one in the chain with a fault policy. Because the FailingService failed, also the (synchronous) ServiceA_NP failed. But because ServicePSAsync_PS is asynchronous, that is where it stopped.


The error can be recovered from there, and in the meantime, the BPM process runs like there is no cloud in the sky.

Because of the asynchronous nature of the ServiceLayer, this is not a decision you should take lightly. For example, statefull BPEL cannot be migrated, so any error in it cannot be fixed for running instances. It therefore might not be the silver bullet you were looking for.
Oracle BPM: Loops and Gateway Struggles
If there is one issue that I see people often struggle with, then it is the use of loops in combination with gateways. The following discusses a few cases.

The following picture shows several loops in combination with a Parallel gateway, of which some are valid and some not. The same holds for the Inclusive gateway.
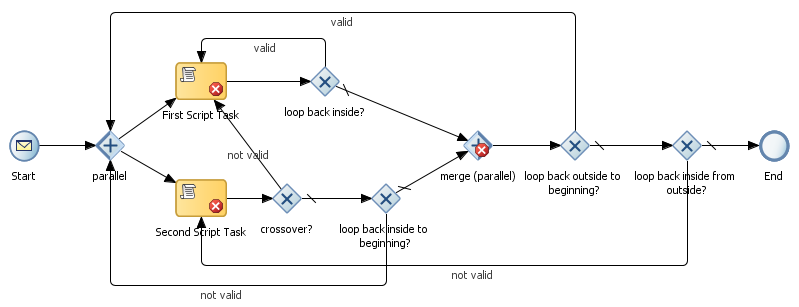
To understand why some loops are valid and other not, you have to realize that at the beginning of a Parallel or Inclusive gateway as many tokens are generated as there are parallel flows that run between the start and end of the gateway. To the BPM engine this translates to 1 or more threads that are instantiated.
No such restrictions are there for an exclusive gateway, because then there is only one token (thread) active at any time.
So in BPMN the following flows are not valid:
- From "crossover?", because you are going to another thread that may already have passed the point that the flow goes to. However, JDeveloper does not prevent you from doing so.
- From "loop back inside to beginning", because at the beginning of the gateway new threads would have to be instantiated for flows of which some threads may already run. JDeveloper should fail validation of such a construct.
- From "loop back inside from outside", because you would then have to go back to a thread already ended in the merge. JDeveloper should fail validation of such a construct.
The flows that are valid in BPMN are:
- From "loop back inside", as you loop back within the same thread.
- From "loop back outside to beginning" as you are re-instantiating a new set of threads for which the previous set already ended.
In case the latter does not work apply patch 23230734.
Oracle BPM 12c: Hide Implementation Details with the Refine Feature
Ever had a case with the Oracle BPM Suite where you wanted to create a BPMN model while hiding the details from the reader? Then the "refine" feature may be what you are looking for. Read on if you want to know more about this feature that has been added since 12c. I actually blogged about it before, but this time I want to also illustrate the impact it has on the flow trace.
The "refine" feature is a way to detail an activity. Basically it is a specialization of the (already in 11g present) embedded subprocess. The difference being that - unlike a normal embedded subprocess - the refined activity keeps the icon of the main activity.
To show this difference take the next example where I hide the details of a Script activity being executed before a User activity is scheduled. When I collapse that embedded subprocess it gets a blue color, hiding this technical detail but also that the main activity (still) is the User activity.


This can somewhat be mitigated by changing the icon of the activity, but the options are pretty limited. Furthermore, this deviates from the standard BPMN notation what some readers might find somewhat disruptive.



Now let's have a look at the refine feature. The use case here is a bit different, in that I want to hide from the reader that a User activity in reality is handled by some other application with some asynchronous interface to send the payload (to of what otherwise would be a normal Human Task) via a Send activity, after which I receive the updated payload and outcome via a Receive activity. In case you wonder why on earth I want to do this: the example is inspired by a real customer case where the BPM process orchestrates system and human interactions of which the latter actually are backed by activities in Siebel.
You refine an activity by chosing "Refine" from the right-mouse-click context menu of the activity itself.

The initial result is some sort of an embedded subprocess to which a User activity has automatically been added, however without a Start and End event.

I can now detail this activity by adding a Send and Receive activity to it. Because I don't wamt implement the User activity I put that in draft mode. Before you criticize how ugly this is, consider this: you still may want to express that the Send and Receive actually are a placeholder of something that is not implemented as a Human Task, but still concerns some implementation of what logically is a User activity.

I can compile and deploy this BPM application without any issue, but ... As it turns out it does not work.

Because of what I consider a bug, the refined activity actually does need a Start and End event, just like a regular Embedded Subprocess. The compiler just forgets to tell you.


Not surprising, as you can see the flow trace is not different than that of a regular Embedded Subprocess. And what you can do with it is also the same, as you can tell from the next iteration in which I have implemented some fallback scenario to schedule a User activity whenever the handling by the other application is not done within some time limit.

And despite all these details, I can still present the activity to the reader as a simple User activity, only difference being the + symbol :-)

The "refine" feature is a way to detail an activity. Basically it is a specialization of the (already in 11g present) embedded subprocess. The difference being that - unlike a normal embedded subprocess - the refined activity keeps the icon of the main activity.
To show this difference take the next example where I hide the details of a Script activity being executed before a User activity is scheduled. When I collapse that embedded subprocess it gets a blue color, hiding this technical detail but also that the main activity (still) is the User activity.


This can somewhat be mitigated by changing the icon of the activity, but the options are pretty limited. Furthermore, this deviates from the standard BPMN notation what some readers might find somewhat disruptive.



Now let's have a look at the refine feature. The use case here is a bit different, in that I want to hide from the reader that a User activity in reality is handled by some other application with some asynchronous interface to send the payload (to of what otherwise would be a normal Human Task) via a Send activity, after which I receive the updated payload and outcome via a Receive activity. In case you wonder why on earth I want to do this: the example is inspired by a real customer case where the BPM process orchestrates system and human interactions of which the latter actually are backed by activities in Siebel.
You refine an activity by chosing "Refine" from the right-mouse-click context menu of the activity itself.

The initial result is some sort of an embedded subprocess to which a User activity has automatically been added, however without a Start and End event.

I can now detail this activity by adding a Send and Receive activity to it. Because I don't wamt implement the User activity I put that in draft mode. Before you criticize how ugly this is, consider this: you still may want to express that the Send and Receive actually are a placeholder of something that is not implemented as a Human Task, but still concerns some implementation of what logically is a User activity.

I can compile and deploy this BPM application without any issue, but ... As it turns out it does not work.

Because of what I consider a bug, the refined activity actually does need a Start and End event, just like a regular Embedded Subprocess. The compiler just forgets to tell you.


Not surprising, as you can see the flow trace is not different than that of a regular Embedded Subprocess. And what you can do with it is also the same, as you can tell from the next iteration in which I have implemented some fallback scenario to schedule a User activity whenever the handling by the other application is not done within some time limit.

And despite all these details, I can still present the activity to the reader as a simple User activity, only difference being the + symbol :-)

Are MicroServices the Death of BPM and Case Management?
When reading about MicroServices you could get the impression that orchestrated business processes or even case management applications will soon become legacy. I seriously doubt that, considering the challenges you will face with creating a landscape of MicroServices that will be able to support some of the characteristics that gave birth to BPM and Case Management in the first place. Also, Martin Fowler's primary guideline concerning MicroServices is "don't even consider MicroServices unless you have a system that's too complex to manage as a monolith". In the following I discuss the issues you might face with Business Process and Case Management in a pure MicroServices architecture. My conclusion being that MicroServices will not be the death of BPMN or Case Management. On the contrary, it probably is going to help delivering on some of their promises we so far seem not always be able to deliver upon.
Business Processes and Cases Are Not MicroServicesLet's face it, BPM is about (stateful) orchestration. MicroServices are supposed to be stateless, and its business capability should not depend on others to complete its work, which makes it like the opposite. In BPMN the order in which activities are executed is prescribed or 'orchestrated' as we say, by 'flows' that go from one point to another. The de facto standard language to express a BPM processes is BPMN, which visualizes this explicitly. With each step the state of the complete flow can be persisted. Service calls should be synchronous when successful completion of the process is dependent on the response, and then errors are handled by the process. In contrast the MicroServices 'design for failure' principle makes them more about 'choreography' and as loosely coupled as possible. Rather than making the working of a MicroService dependent on a synchronous call to another service, communication preferably is based on events. By definition there is no such thing as persisting the 'state of a process', and no over-arching process to handle errors.
Unlike BPMN, Case Management is about choreography, but - much more than a number of interacting MicroServices - still predictable in that you know up-front which type activities may be involved, and the rules that determine this. Similar to BPMN, with CMMN you can visualize this to some extent. And similar to BPM also the state of a case is persisted, supporting that you can see what has been done by whom, what the current running activities are, and - based on the model and the rules - you can predict what might happen next. A successful completion of a case depends upon the completion of the individual activities. So in spite of its characteristic of choreography also Case Management contrasts MicroServices in more than one way.
MicroService ChallengesWhen thinking about the highly flexible, however for the observer often unpredictable flow of events in case of a MicroServices architecture, where the completion of an instance of one MicroService can trigger any number of instances of other MicroServices, you start to realize some of the challenges you will face with business processes that are only supported by MicroServices including - but not limited to - the following.
Process/Case IntrospectionAs stated before, one thing a business process and case management support is that you can introspect the state of the process or case. Where is it, what has already happened, and what will/might happen next? To achieve the same with MicroServices you will have to realize some central, coordinating MicroService or Aggregator that somehow has to be fed with the state of MicroService executions, can correlate them in some way, and present them in a context that can be understood by the user. For example, in case of a complex order handling business process (that can span hours our days) this implies that it is able to correlate MicroService executions using some common business indicator like an order id. This implies a dependency of this central MicroService on the other ones to publish the states of their execution with a reference to the order id. That introduces some interesting challenges regarding how to define the bounded context of such a central MicroService and how to implement the anti-corruption layer to make the entities of the individual MicroServices non-intrusive to that of the central one.
But let's ignore that for now. For this central MicroService to be able to present this state to the user so that he/she understands what happened when, why, by whom or what, and what might happen next, it must have some notion of a 'business process' (or case). It might be my lack of imagination, but I cannot picture how this can work as there is no central coordinator to rule them all. A concrete example from my practice is a Move Natural Person process in a bank. Next to a bank account this person might also have a credit card, a mortgage, and several insurances. Some of these product can be moved by just changing the address, but you cannot do that with a mortgage for example. For a bank moving a person or organization is one of the more complex processes, and whenever a customer calls to inquire what the status is, it is imperative for the bank employee to have this overall view. How to know that all relevant MicroServices have been initiated? Of course, I can picture some solution where all MicroServices have to publish events to some central "hub" and from there support some navigation to dashboards of the individual MicroServices, But I also start to see some sort of a dependency that you would try to avoid in a MicroServices architecture.
Process/Case OperationOperations will have a similar problem as the business has when they have to operate the process or case. If a process is stuck from a technical perspective, in which MicroService is that? Practically also this type of concern can only be addressed when to some extend there is a sort of common way to log errors, collect those and present them in a consolidated way. Also something that is in conflict with the principle of decentralization, as each MicroService is supposed to be operated independently.
Process/Case Modeling and TestingAnd what about modeling and testing a process or case? Capturing how a case may evolve over time in CMMN is already more difficult for the reader to understand than a BPMN process design. But how a process would unfold in a pure MicroServices environment you can only understand if you would model that in some similar way. But in a pure MicroServices architecture that does not seem to make any sense. And if you don't model it you surely will have difficulties testing it.
Authorization & AuthenticationAnother challenge I would like to point out is authorization and authentication. In BPMN there are swimlanes that correspond to roles that you can assign people to. By using a central repository of these roles you can implement a consistent way of authentication and authorization. In Case Management there are similar concepts (e.g. knowledge workers). How to implement this for a process only consisting of MicroServices when this implies a centralized authentication and authorization model?
Granted, MicroServices is relatively new, still in the hype phase, and over time some of these challenges will be addressed. This will result in new patterns, and frameworks and tools to support that. But I seriously doubt this will ever address all the requirements that are naturally addressed by BPM or Case Management. So over time I believe both will survive the MicroServices hype, although I see Case Management gaining ground over BPM.
MicroServices Values for BPM and Case ManagementHowever, all this does not mean there is no value in adapting at least some of the principles related to MicroServices to BPM and Case Management applications. I can see how it could address some of the issues I faced with processes that are almost too big to handle, and issues with reuse of services and the impact that had on agility. Since then I much more tend to:
Business Processes and Cases Are Not MicroServicesLet's face it, BPM is about (stateful) orchestration. MicroServices are supposed to be stateless, and its business capability should not depend on others to complete its work, which makes it like the opposite. In BPMN the order in which activities are executed is prescribed or 'orchestrated' as we say, by 'flows' that go from one point to another. The de facto standard language to express a BPM processes is BPMN, which visualizes this explicitly. With each step the state of the complete flow can be persisted. Service calls should be synchronous when successful completion of the process is dependent on the response, and then errors are handled by the process. In contrast the MicroServices 'design for failure' principle makes them more about 'choreography' and as loosely coupled as possible. Rather than making the working of a MicroService dependent on a synchronous call to another service, communication preferably is based on events. By definition there is no such thing as persisting the 'state of a process', and no over-arching process to handle errors.
Unlike BPMN, Case Management is about choreography, but - much more than a number of interacting MicroServices - still predictable in that you know up-front which type activities may be involved, and the rules that determine this. Similar to BPMN, with CMMN you can visualize this to some extent. And similar to BPM also the state of a case is persisted, supporting that you can see what has been done by whom, what the current running activities are, and - based on the model and the rules - you can predict what might happen next. A successful completion of a case depends upon the completion of the individual activities. So in spite of its characteristic of choreography also Case Management contrasts MicroServices in more than one way.
MicroService ChallengesWhen thinking about the highly flexible, however for the observer often unpredictable flow of events in case of a MicroServices architecture, where the completion of an instance of one MicroService can trigger any number of instances of other MicroServices, you start to realize some of the challenges you will face with business processes that are only supported by MicroServices including - but not limited to - the following.
Process/Case IntrospectionAs stated before, one thing a business process and case management support is that you can introspect the state of the process or case. Where is it, what has already happened, and what will/might happen next? To achieve the same with MicroServices you will have to realize some central, coordinating MicroService or Aggregator that somehow has to be fed with the state of MicroService executions, can correlate them in some way, and present them in a context that can be understood by the user. For example, in case of a complex order handling business process (that can span hours our days) this implies that it is able to correlate MicroService executions using some common business indicator like an order id. This implies a dependency of this central MicroService on the other ones to publish the states of their execution with a reference to the order id. That introduces some interesting challenges regarding how to define the bounded context of such a central MicroService and how to implement the anti-corruption layer to make the entities of the individual MicroServices non-intrusive to that of the central one.
But let's ignore that for now. For this central MicroService to be able to present this state to the user so that he/she understands what happened when, why, by whom or what, and what might happen next, it must have some notion of a 'business process' (or case). It might be my lack of imagination, but I cannot picture how this can work as there is no central coordinator to rule them all. A concrete example from my practice is a Move Natural Person process in a bank. Next to a bank account this person might also have a credit card, a mortgage, and several insurances. Some of these product can be moved by just changing the address, but you cannot do that with a mortgage for example. For a bank moving a person or organization is one of the more complex processes, and whenever a customer calls to inquire what the status is, it is imperative for the bank employee to have this overall view. How to know that all relevant MicroServices have been initiated? Of course, I can picture some solution where all MicroServices have to publish events to some central "hub" and from there support some navigation to dashboards of the individual MicroServices, But I also start to see some sort of a dependency that you would try to avoid in a MicroServices architecture.
Process/Case OperationOperations will have a similar problem as the business has when they have to operate the process or case. If a process is stuck from a technical perspective, in which MicroService is that? Practically also this type of concern can only be addressed when to some extend there is a sort of common way to log errors, collect those and present them in a consolidated way. Also something that is in conflict with the principle of decentralization, as each MicroService is supposed to be operated independently.
Process/Case Modeling and TestingAnd what about modeling and testing a process or case? Capturing how a case may evolve over time in CMMN is already more difficult for the reader to understand than a BPMN process design. But how a process would unfold in a pure MicroServices environment you can only understand if you would model that in some similar way. But in a pure MicroServices architecture that does not seem to make any sense. And if you don't model it you surely will have difficulties testing it.
Authorization & AuthenticationAnother challenge I would like to point out is authorization and authentication. In BPMN there are swimlanes that correspond to roles that you can assign people to. By using a central repository of these roles you can implement a consistent way of authentication and authorization. In Case Management there are similar concepts (e.g. knowledge workers). How to implement this for a process only consisting of MicroServices when this implies a centralized authentication and authorization model?
Granted, MicroServices is relatively new, still in the hype phase, and over time some of these challenges will be addressed. This will result in new patterns, and frameworks and tools to support that. But I seriously doubt this will ever address all the requirements that are naturally addressed by BPM or Case Management. So over time I believe both will survive the MicroServices hype, although I see Case Management gaining ground over BPM.
MicroServices Values for BPM and Case ManagementHowever, all this does not mean there is no value in adapting at least some of the principles related to MicroServices to BPM and Case Management applications. I can see how it could address some of the issues I faced with processes that are almost too big to handle, and issues with reuse of services and the impact that had on agility. Since then I much more tend to:
- Design and implement sub-processes as deployable units of their own.
- Push more of the other logic to a deployable unit of its own than I already did.
- Let data models be less intrusive to integrations (i.e. chose the Anti-Corruption pattern with small Bounded Contexts over the Conformist pattern), and address data mapping challenges in the (anti-corruption layer of the) individual services rather than in some integration layer (smart endpoints / dumb pipes).
- Apply the Tolerant Reader pattern more that I already did
- Copy and paste code if that prevents unnecessary impact of a change on some shared component.
Oracle SOA/BPM 12c: Contract WSDL Only in MDS?
In this posting I will discuss if it is a good idea to only have a (contract) WSDL in the MDS, and let your implementing composite point to that, instead of having a WSDL in the project itself (as well).
When developing SCA composites with JDeveloper, initially your WSDL will be in the project of the composite. Some people put a contract WSDL in the MDS, and then let the code of the SCA composite point to that (using an "oramds:/" reference), while removing the local one at the same time. The idea behind this that all projects using it, including the service provider itself, use exactly the same WSDL, and with that prevent conflicts. Good thinking but this is what you should know before doing so.
First the good news. 11g required that there was also a local WSDL. If you moved the WSDL to the MDS it would generate a wrapper WSDL that would be used in the code itself. The wrapper would then import the contract WDSL. Apart from the feeling that these wrappers seem to add overhead, I also experienced with some versions of JDeveloper that the wrapper and the contract WSDL could get out-of-sync. Sometimes fixing compilation issues because of that could become a difficult job indeed. With 12c this has improved. The wrapper WSDL is no longer generated, and so far I have not been able to reproduce any of the synchronization issues caused by changes in the project.
However, you may have some issues with control over publishing any update of the contract WSDL. If you need to update the WSDL, for example because you want to add an operation (not applicable to BPEL by the way) you have to change the contract WSDL in the MDS first. If you commit that to your version control system then somebody else could update it, and get the impression that the new operation is ready to use, while you still have to start implementing it.
There are two ways to work around it.
One option is to work with an MDS project that is specific to your composite. Meaning that, instead of 1 single project that you use to deploy all MDS artifacts at the same time, you create a small-scoped MDS project that contains all artifacts for one specific composite. That MDS project you add to the same workspace as the composite itself. So you can change the contract WSDL and work on the implementation without hindering anyone else until they need it. But then they get the new contract WSDL together with the updated composite itself.
Of course this option won't work when you share one single development environment, but that is a bad practice anyway. It also may require a change of the way you deploy the MDS and composites. Using tooling like Maven can help out here.
If this option does not work for you, then consider having a local as well as a contract WSDL. You change the local WSDL first, implement the new operation, and only after you are ready replace the contract WSDL.
In either case it is highly recommended that all public schemas are in the MDS only, before releasing the composite for usage. Otherwise you may encounter runtime issues with clashing element definitions, which you may only encounter when it is too late, for example after a restart of the server.
When developing SCA composites with JDeveloper, initially your WSDL will be in the project of the composite. Some people put a contract WSDL in the MDS, and then let the code of the SCA composite point to that (using an "oramds:/" reference), while removing the local one at the same time. The idea behind this that all projects using it, including the service provider itself, use exactly the same WSDL, and with that prevent conflicts. Good thinking but this is what you should know before doing so.
First the good news. 11g required that there was also a local WSDL. If you moved the WSDL to the MDS it would generate a wrapper WSDL that would be used in the code itself. The wrapper would then import the contract WDSL. Apart from the feeling that these wrappers seem to add overhead, I also experienced with some versions of JDeveloper that the wrapper and the contract WSDL could get out-of-sync. Sometimes fixing compilation issues because of that could become a difficult job indeed. With 12c this has improved. The wrapper WSDL is no longer generated, and so far I have not been able to reproduce any of the synchronization issues caused by changes in the project.
However, you may have some issues with control over publishing any update of the contract WSDL. If you need to update the WSDL, for example because you want to add an operation (not applicable to BPEL by the way) you have to change the contract WSDL in the MDS first. If you commit that to your version control system then somebody else could update it, and get the impression that the new operation is ready to use, while you still have to start implementing it.
There are two ways to work around it.
One option is to work with an MDS project that is specific to your composite. Meaning that, instead of 1 single project that you use to deploy all MDS artifacts at the same time, you create a small-scoped MDS project that contains all artifacts for one specific composite. That MDS project you add to the same workspace as the composite itself. So you can change the contract WSDL and work on the implementation without hindering anyone else until they need it. But then they get the new contract WSDL together with the updated composite itself.
Of course this option won't work when you share one single development environment, but that is a bad practice anyway. It also may require a change of the way you deploy the MDS and composites. Using tooling like Maven can help out here.
If this option does not work for you, then consider having a local as well as a contract WSDL. You change the local WSDL first, implement the new operation, and only after you are ready replace the contract WSDL.
In either case it is highly recommended that all public schemas are in the MDS only, before releasing the composite for usage. Otherwise you may encounter runtime issues with clashing element definitions, which you may only encounter when it is too late, for example after a restart of the server.
Oracle BPM 11g/12c: How to Catch an Event in the Same Process
A customer of mine was kind of surprised that when you throw an event in a component of a SCA composite, that the same component cannot catch that event and act upon it. This is a known limitation, for which there is a work-around, which I will discuss in this article.
The work-around is quite simple: another loosely coupled component in the same composite can listen to the event, so all you have to do is to create a BPEL or BPM process as-a-service that is subscribed to the event, and that interacts with the main process that you want to act upon it.
To show that a component cannot listen to its own event, and that the work-around actually works, I used the following test process. No worries, it looks more complex than it is.
The parent process above takes a parameter as input so that I can let it execute either one of the following three scenarios, which consist of throwing an event and then catch it:

There are 4 parallel flows between the OR-gateways:
Only 1 of the first 3 flows is activated at any time, while the last flow (with the events) is always activated. Furthermore the parent process has an Event Sub-process that listens to the event that is thrown by the Throw Internal Event event.
The reusable child is also very basic. It has a User activity to make it pause and wait for the event. It also has a an Event Sub-process that listens to the event that is thrown by the Throw Internal Event for Child event. If it is activated, it will map some variable to itself (to see something concrete in the audit trail), and then it will withdraw the Wait task.
 The (child) process as-a-service does the same as the reusable child, except for that it has a start and end event which makes it an asynchronous BPM process as-a-service.
The (child) process as-a-service does the same as the reusable child, except for that it has a start and end event which makes it an asynchronous BPM process as-a-service.
 Now when you start an instance of the parent for each of the 3 scenarios, the result in Enterprise Manager is as below:
Now when you start an instance of the parent for each of the 3 scenarios, the result in Enterprise Manager is as below:
 The instance at the bottom (1450067) belongs to the scenario where the parent tries to catch the event. Which fails as you can see by the fact that it is still running. And yes, I did make sure the Catch Event is correlated properly to the Start Event. The next instance (1450068) is the one that catches it, but as you can see they both are still running. When clicking on the second one, it somehow figured out that both instances are related, but the first instance won't act upon it.
The instance at the bottom (1450067) belongs to the scenario where the parent tries to catch the event. Which fails as you can see by the fact that it is still running. And yes, I did make sure the Catch Event is correlated properly to the Start Event. The next instance (1450068) is the one that catches it, but as you can see they both are still running. When clicking on the second one, it somehow figured out that both instances are related, but the first instance won't act upon it.
The third instance (1450069) is that of the scenario where the reusable child tries to catch the event. From the fact that there is no other instance, you can see that it does not even listen to the event.
The fourth instance (1450070) is that of the parent that calls the child process as-a-service. The fifth (top) instance (1450071) is that of the child that catches the event, and then calls back the parent instance. As you can see, those are the only two instances that actually completed. So only in this scenario it actually works.
The work-around is quite simple: another loosely coupled component in the same composite can listen to the event, so all you have to do is to create a BPEL or BPM process as-a-service that is subscribed to the event, and that interacts with the main process that you want to act upon it.
To show that a component cannot listen to its own event, and that the work-around actually works, I used the following test process. No worries, it looks more complex than it is.
The parent process above takes a parameter as input so that I can let it execute either one of the following three scenarios, which consist of throwing an event and then catch it:
- In the same (parent) process model
- In a reusable sub-process (called through a Call activity)
- In a process as-a-service that is called through a Send / Receive activity

There are 4 parallel flows between the OR-gateways:
- The top flow has a Wait User activity to make it pause and waits for the event.
- The second flow has a Call Child Call activity which calls the reusable process below.
- The third flow has the Send/Receive activities to call the process as-a-service below.
- The bottom one waits 2 seconds to give one of the other flows time to be activated, and then throws either one of two events, depending on whether I want to test catching it in the parent or in the reusable child (for this you cannot use the same event type, that's why).
Only 1 of the first 3 flows is activated at any time, while the last flow (with the events) is always activated. Furthermore the parent process has an Event Sub-process that listens to the event that is thrown by the Throw Internal Event event.
The reusable child is also very basic. It has a User activity to make it pause and wait for the event. It also has a an Event Sub-process that listens to the event that is thrown by the Throw Internal Event for Child event. If it is activated, it will map some variable to itself (to see something concrete in the audit trail), and then it will withdraw the Wait task.



The third instance (1450069) is that of the scenario where the reusable child tries to catch the event. From the fact that there is no other instance, you can see that it does not even listen to the event.
The fourth instance (1450070) is that of the parent that calls the child process as-a-service. The fifth (top) instance (1450071) is that of the child that catches the event, and then calls back the parent instance. As you can see, those are the only two instances that actually completed. So only in this scenario it actually works.