
Donal Daly
Random thoughts on Big Data Analytics and the Big Data Marketplace in GeneralAnonymoushttp://www.blogger.com/profile/10733509547372080487noreply@blogger.comBlogger29125
Updated: 1 hour 31 min ago
Running Teradata Aster Express on a MacBook Pro
To those people who know me, know that I am complete Apple geek. Teradata's supports BYOD, so naturally I have a MacBook Pro. Why wouldn't I want to run Aster Express on it :-)
The configuration was surprisingly easy once I worked out how!
Prerequisites
You get to the Network Editor from Preferences. Create a new network adapter vmnet2 as shown in the screen shot below:

Then make sure that for both the Queen and Worker VMWare images you assign vmnet2 as your network adapter as illustrated in the screenshot below:

To run the Aster Management console point your favourite browser to https://192.168.100.100 You may ignore any website security certificatewarnings and continue to the website.
The configuration was surprisingly easy once I worked out how!
Prerequisites
- 4 GB memory - (I have 8GB in mine)
- At least 20 GB free disk space
- OS: I am running Mac OS X 10.8.2
- VMware Player: - Buy VMWare Fusion. I have version 5.0.2 (900491)
- ** Make sure to order the professional version, as only this version has the new
- ** Network Editor feature
- 7-Zip: To extract (or uncompress) the Aster Express package.
You get to the Network Editor from Preferences. Create a new network adapter vmnet2 as shown in the screen shot below:

Then make sure that for both the Queen and Worker VMWare images you assign vmnet2 as your network adapter as illustrated in the screenshot below:

That is really the only changes you need to make. Follow the rest of the instructions as outlined in the Getting Started with Aster Express 5.0 to get your Aster nCluster up and running.
If you have 8GB of memory you might decide to allocate 2GB of memory to each VM instead of the 1GB which is the default. Again you can set this in the settings for each VMWare image. I also run the utility Memory Clean (available for free from the App Store). You would be amazed how much a memory hog FireFox and Safari can be. I normally shutdown most other running programs when I am working with Aster Express to give me the best user experience.
You will also find mac versions of act and ncluster_loader in /home/beehive/clients_all/mac. I just copy them to my host. In fact, Once I start up the VMWare images, I do most everything natively from the Mac.
In future posts I plan to cover the following topics:
- How to scale your Aster Express nCluster and make it more reliable
- Demo: From Raw Web log to Business Insight
- Demo: Finding the sentiment in Twitter messages
If there are topics you would like me to cover in the future, then just let me know.
My perspective on the Teradata Aster Big Analytics Appliance
 Aster Big Analytics Appliance 3H
Aster Big Analytics Appliance 3HBy now, no doubt you have heard the announcement of our new Teradata Aster Big Analytics Appliance. In the interests of full disclosure, I work for Teradata within the Aster CoE in Europe. Prior to joining Teradata, I was responsible for a large complex Aster environment which was built on commodity servers in excess of 30 TB of usable data with a 24 x 7 style operational environment. So my perspective in this post is from that standpoint and also recalling the time when we went under a hardware refresh and software upgrade.
OK, First of all you procure 30 servers and at least two network switches (for redundancy). When you receive them, it up to your data centre team to rack them and cable them up. Next, check the firmware on each system is the same, surprise, surprise they aren't, so a round of upgrades later, then you configure the raid controllers. In this case we went for Raid 0 which maximises space, more on that choice later...
Then it is over to the network team, to configure the switches and the VLAN we are going to use. We then put on a basic Linux image on the servers so we can carry out some burn in tests, to make sure all the servers have a similar performance profile. Useful tests, as we found two servers whose raid controllers were not configured correctly. It was the result of human error, I guess manually doing 30 servers can get boring. This burns through a week, before we can install Aster, configure the cluster and bring all the nodes online to start the data migration process. Agreed, this is a one off cost, but in this environment, we are responsible for all hardware issues, network issues, Linux issues, with the Vendor just supporting Aster. Many customers never count that cost or possible outages that might be avoided because of these one off configurations.
We had some basic system management as these are commodity servers but nothing as sophisticated as Teradata Server Management and the Teradata Vital Infrastructure. I like that with the Server management software it allows me to manage 3 clusters within the Rack logically (e.g. Test, Production, Backup). I also like the proactive monitoring, as it is likely they will identify issues prior to them becoming an outage for us, or an issue found with one customer can be checked against all customers. If you build and manage your own environment, you don't get that benefit.
Your next consideration should be when looking at an appliance, is it leading edge and how much thought has gone into the configuration? The Appliance 3H is a major step forward from Appliance 2. From a CPU perspective, it has the very latest processors from Intel, dual 8 core Sandy Bridge @ 2.6GHz. Memory has increased to 256GB. Connectivity between nodes is now provided by Infiniband at 40Gb/s. Disk drives are the newer 2.5 size, enabling more capacity per node. Worker nodes using 900GB, while backup and the Hadoop nodes leveraging larger 3TB drives. RAID 5 for Aster and RAID 6 for the backup and Hadoop nodes. Also with the larger cabinet size, enables better data centre utilisation with the higher density that is possible.
I also like the idea of providing integrated Backup nodes as well, previously Aster just had the parallel backup software only, you had to procure your own hardware and manage it. We also know that all of these components have been tested together, so I am benefiting from their extensive testing, rather than building and testing reference configurations myself.
What this tells me, is that Teradata, can brings advances in hardware quickly to the marketplace. Infiniband will make make an important difference. For example, for very large dimension tables, that I have decided against replicating, joins will run much faster. Also I expect positive impact on Backups. In my previous environment, it took us about 8 hours for a full backup of 30 TB or so. Certainly the parallel nature of their backup software could soak-up all the bandwidth on a 10GB connection, so we had to throttle it back. On the RAID choices, I absolutely concur with the RAID 5 choice. If I was building my own 30 node cluster again I wouldn't have it any other way. While the replication capabilities in Aster protects me against at least any single node failure, a disk failure, will bring that node out of the cluster, until the disk is replaced and the node is rebuilt and brought back online. When you have 30+ servers each with 8 drives (240+ disk drives) the most common failure will be the disk drive. With RAID 5, you can replace the drive, without any impact on the cluster at all, and you still have the replication capabilities to protect yourself from multiple failures.
I also like the option of being able to have an Hadoop cluster tightly integrated as part of my configuration. For example if I have to store a lot of 'grey data' e.g. log/audit files etc for compliance reasons, I can leverage a lower cost of storage and still do batch transformations and analysis as required. Bring a working set of data (last year for example) for deeper analytics. With the transparent capabilities of SQL-H, I can extend those analytics into my Hadoop environment as required.
Of course purchasing an appliance, is a more expensive route than procuring it, building and configuring it all yourself. However, most enterprise are not hobbyists, and building this sort of infrastructure, is not their core competence nor is is bringing value to their business. They should be focused on the Time to Value and with the Teradata Aster Big Analytics appliance the time to value will be quick, as everything, is prebuilt, configured, tested and ready to go, to accept data and start performing analytics on it. As I talk to customers across Europe this message is being well received when you talk through the details.
I'll leave you with this thought, one aspect of big data that I don't hear enough of is Value. To me, the dimension of Volume, Variety, Velocity and Complexity are not very interesting if you are not providing value by means of actionable insights. I believe every enterprise customer needs a discovery platform capable of executing the analytics that can provide them an important competitive edge over their competition. This platform should have the capability to handle structured as well as multi-structured data. It should provide a choice of analytics, whether they be SQL based, MapReduce or statistical functions. It should provide a host of prebuilt functions to enable rapid progress. It should be a platform that can appeal to power users in the business, by having a SQL interface and that will work with their existing visualisation tools to our most sophisticated data scientists, by providing them a rich environment to develop their own custom functions as necessary, while enabling them to benefit both from the power of SQL and Map Reduce to build out these new capabilities. In summary that is why I am so excited to be talking with customers and prospects about Teradata Aster Big Analytics Appliance.
Aster integration into the Teradata Analytical ecosystem continues at pace…
Not long after Teradata acquired Aster in April last year we outlined a roadmap as to how Aster would integrate into the Teradata Analytical ecosystem.

This example below shows the load_from_teradata connector being called from within an Aster SQL query:
SELECT userid, age, sessionid,pageid
FROM nPath(
ON (
select * fromclicks,
load_from_teradata(
on mr_driver tdpid(‘EDW')
credentials ('tduser’)
query(‘SELECT userid, age, gender, income FROM td_user_tbl;')
) T
where clicks.userid =T.userid )
PARTITION BY userid, sessionid
RESULT ( FIRST(age of A) as age, … )
This example shows the load_to_teradata component, with analytic processing on Aster withresults being sent to a Teradata target table:
SELECT *
FROM load_to_teradata(
ON ( aster_target_customers )
tdpid (‘dbc’)
username('tduser’)
password(‘tdpassword')
TARGET_TABLE(‘td_target_customer_table’)
);
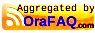
Viewpoint IntegrationWe have just announced Aster integration with Teradata Viewpoint, with release of 14.01 of Viewpoint and Aster 5.0. Viewpoint's single operational view (SOV) monitoring has been extended to include support for Teradata Aster. Teradata wanted to leverage as many of the existing portlets as possible for easier navigation, familiarity, and support for theViewpoint SOV strategy. So the following existing portlets were extended to include support for Aster:
• System Health
• Query Monitor
• Capacity Heatmap
• Metrics Graph
• Metrics Analysis
• Space Usage
• Admin - Teradata Systems
However not all the needs of Teradata Aster's differing architecture made sense to put into an existing portlet. Therefore there are two new Aster specific portlets in this release.
• Aster Completed Processes
• Aster Node Monitor
Some screenshots:



Stay tuned for some very exciting news coming next week...

Aster-Teradata Adapter
Clearly, the first priority was to delivera high speed interconnect between Aster And Teradata. The Aster-Teradata adapter is based on the Teradata Parallel Transporter API and provides ahigh-speed link to transfer data between the two platforms. It allows parallel data transfers between Aster and Teradata, with each Aster Worker connecting toa Teradata AMP. This connector is part of the Aster SQL-MR library, with all data transfers initiated through AsterSQL.
The Aster-Teradata adapter offers fast and efficient data access. Users can build views in the Aster Database on tables stored in Teradata. Aster Database users can access and perform joins on Teradata-stored data as if it were stored in the Aster Database. Data scientists can run Aster’s native analytic modules,such as nPath pattern matching, to explore data in the Teradata Integrated DataWarehouse. Users now have the capability to Investigate & Discover in Teradata Aster, then Integrate & Operationalize in the Data Warehouse.This example below shows the load_from_teradata connector being called from within an Aster SQL query:
SELECT userid, age, sessionid,pageid
FROM nPath(
ON (
select * fromclicks,
load_from_teradata(
on mr_driver tdpid(‘EDW')
credentials ('tduser’)
query(‘SELECT userid, age, gender, income FROM td_user_tbl;')
) T
where clicks.userid =T.userid )
PARTITION BY userid, sessionid
RESULT ( FIRST(age of A) as age, … )
This example shows the load_to_teradata component, with analytic processing on Aster withresults being sent to a Teradata target table:
SELECT *
FROM load_to_teradata(
ON ( aster_target_customers )
tdpid (‘dbc’)
username('tduser’)
password(‘tdpassword')
TARGET_TABLE(‘td_target_customer_table’)
);
Viewpoint IntegrationWe have just announced Aster integration with Teradata Viewpoint, with release of 14.01 of Viewpoint and Aster 5.0. Viewpoint's single operational view (SOV) monitoring has been extended to include support for Teradata Aster. Teradata wanted to leverage as many of the existing portlets as possible for easier navigation, familiarity, and support for theViewpoint SOV strategy. So the following existing portlets were extended to include support for Aster:
• System Health
• Query Monitor
• Capacity Heatmap
• Metrics Graph
• Metrics Analysis
• Space Usage
• Admin - Teradata Systems
However not all the needs of Teradata Aster's differing architecture made sense to put into an existing portlet. Therefore there are two new Aster specific portlets in this release.
• Aster Completed Processes
• Aster Node Monitor
Some screenshots:


{kind=link}


Don't be left in the dark... Exciting Teradata Aster Announcement coming soon

Believe me, it is going to be amazing...
The Big Data Analytics Landscape
As a technologist and evangelist working in the big data marketplace it is certainly exciting. I am excited by the new products we are bringing to market and how this new functionality really helps to bridge the gap for Enterprises adoption. It is also surreal, in terms of the number of blog posts, tweets on Big Data and there seems to be a new big data conference cropping up on a weekly basis across Europe :-)
It is interesting to monitor other vendors in the marketplace and how they position their offerings. There is certainly a lot of clever marketing going on (that I believe in time will show a lack of substance) and some innovation too, . You know who you are.... But jump aboard the bandwagon. Just because you might have Hadoop and your database + Analytics within the same rack that doesn't mean they are integrated.
It is also interesting the fervor that people bring when discussing open source products. Those people who know me, know that I am a long time UNIX guru over 20 years from the early BSD distributions to working with UNIX on mainframes, to even getting minix to work on PC's before Linux came along. Fun times, but I was young free and single and enjoyed the technical challenge. I was also working in a research department in a university. However the argument that Hadoop is free and easy to implement and will one day replace data warehousing, doesn't ring true for me. Certainly it is true is has a place, and does provide value, but it doesn't come at no cost. Certainly Hortonworks and Cloudera provide distributions that are reducing the installation/configuration and management effort, but you have multiple distributions, starting to go in different directions? MapR for example?
How many enterprises really want to get that involved in running and maintaining this infrastructure. Surely they should be focused on identify new insights that provides business benefits or gives greater competitive advantage. IT has an important role to play, but it will be the business users ultimately that need to leverage the platform to gain these insights.
It is no use getting insights, if you don't take action on them either.
Insight gained from big data analytics should be fed into existing EDW (if they exist) so they can enhance what you already have and the EDW provides you with a better means of operationalizing the results.
I say to those people who think Hive is a replacement for SQL, not yet it ain't, it doesn't provide the completeness or performance that a pure SQL engine can provide. You don't replace 30+ years of R&D that quickly...
To the NoSQL folks, this debate is taking on religious fervour at times, It has a role, but I don't see it replacing the relational database overnight either.
In a previous role I managed a complex DB Environment that included a Big Data platform for a company that operated in the online gaming marketplace in a very much 24 X 7 environment, with limited downtime. It was the bleeding edge at times, growing very fast. If we had Teradata Aster 5.0 then, my life would have been so much easier. Se had an earlier release but we learned a lot. We proved the value of SQL combined with the Map Reduce programming paradigm. We saw the ease of scaling and reliability, We delivered important insights into various types of fraud, and took action on them, which yielded positive kudos for the company and increased player trust, which is very important in an online marketplace. We also were able to leverage the platform for an novel ODS requirement and had both executing simultaneously along with various ad-hoc queries. I was also lucky then and since to meet real visionaries, like Mayank and Tasso which gives you confidence in the approach and the future direction
When you think of big data analytics, it just not just about multi structure data or new data sources. Using SQL/MR for example may be the most performant way to yield new insights from existing relational data. Also consider what 'grey data' already exists within your organisations, it maybe easier to tap into that first, before sourcing new data feeds. The potential business value should drive that decision though.
Do not under estimate the important of having a discovery platform as you tackle these new Big Data Challenges. Yes, you will probably need new people or even better, train existing analysts to take on these new skills and grow your own data scientists. The ease of this approach, will be in how feature rich your discovery platform is, How many built in and useful analytical functions are provided to get you started, before you may have to develop specific ones of your own.
I suppose, some would say I am rambling with these comments and not expressing them very elegantly, but help is at hand :-). We recently put together a short webinar, I think it is about 20 minutes duration.
The Big Data Analytics Landscape: Trends, Innovations and New Business Value, featuring Gartner Research Vice President Merv Adrian and Teradata Aster Co-President Tasso Argyros. In the video, Merv and Tasso, answer these questions and more, including how organizations can find the right solution - to make smarter decisions, take calculated risks, and gain deeper insights than their industry peers.
What do you think?
For me it is all about the analytics and the new insights that can be gained and acted upon
It is interesting to monitor other vendors in the marketplace and how they position their offerings. There is certainly a lot of clever marketing going on (that I believe in time will show a lack of substance) and some innovation too, . You know who you are.... But jump aboard the bandwagon. Just because you might have Hadoop and your database + Analytics within the same rack that doesn't mean they are integrated.
It is also interesting the fervor that people bring when discussing open source products. Those people who know me, know that I am a long time UNIX guru over 20 years from the early BSD distributions to working with UNIX on mainframes, to even getting minix to work on PC's before Linux came along. Fun times, but I was young free and single and enjoyed the technical challenge. I was also working in a research department in a university. However the argument that Hadoop is free and easy to implement and will one day replace data warehousing, doesn't ring true for me. Certainly it is true is has a place, and does provide value, but it doesn't come at no cost. Certainly Hortonworks and Cloudera provide distributions that are reducing the installation/configuration and management effort, but you have multiple distributions, starting to go in different directions? MapR for example?
How many enterprises really want to get that involved in running and maintaining this infrastructure. Surely they should be focused on identify new insights that provides business benefits or gives greater competitive advantage. IT has an important role to play, but it will be the business users ultimately that need to leverage the platform to gain these insights.
It is no use getting insights, if you don't take action on them either.
Insight gained from big data analytics should be fed into existing EDW (if they exist) so they can enhance what you already have and the EDW provides you with a better means of operationalizing the results.
I say to those people who think Hive is a replacement for SQL, not yet it ain't, it doesn't provide the completeness or performance that a pure SQL engine can provide. You don't replace 30+ years of R&D that quickly...
To the NoSQL folks, this debate is taking on religious fervour at times, It has a role, but I don't see it replacing the relational database overnight either.
In a previous role I managed a complex DB Environment that included a Big Data platform for a company that operated in the online gaming marketplace in a very much 24 X 7 environment, with limited downtime. It was the bleeding edge at times, growing very fast. If we had Teradata Aster 5.0 then, my life would have been so much easier. Se had an earlier release but we learned a lot. We proved the value of SQL combined with the Map Reduce programming paradigm. We saw the ease of scaling and reliability, We delivered important insights into various types of fraud, and took action on them, which yielded positive kudos for the company and increased player trust, which is very important in an online marketplace. We also were able to leverage the platform for an novel ODS requirement and had both executing simultaneously along with various ad-hoc queries. I was also lucky then and since to meet real visionaries, like Mayank and Tasso which gives you confidence in the approach and the future direction
When you think of big data analytics, it just not just about multi structure data or new data sources. Using SQL/MR for example may be the most performant way to yield new insights from existing relational data. Also consider what 'grey data' already exists within your organisations, it maybe easier to tap into that first, before sourcing new data feeds. The potential business value should drive that decision though.
Do not under estimate the important of having a discovery platform as you tackle these new Big Data Challenges. Yes, you will probably need new people or even better, train existing analysts to take on these new skills and grow your own data scientists. The ease of this approach, will be in how feature rich your discovery platform is, How many built in and useful analytical functions are provided to get you started, before you may have to develop specific ones of your own.
I suppose, some would say I am rambling with these comments and not expressing them very elegantly, but help is at hand :-). We recently put together a short webinar, I think it is about 20 minutes duration.
The Big Data Analytics Landscape: Trends, Innovations and New Business Value, featuring Gartner Research Vice President Merv Adrian and Teradata Aster Co-President Tasso Argyros. In the video, Merv and Tasso, answer these questions and more, including how organizations can find the right solution - to make smarter decisions, take calculated risks, and gain deeper insights than their industry peers.
- How do you cost-effectively harness and analyze new big data sources?
- How does the role of a data scientist differ from other analytic professionals?
- What skills does the data scientist need?
- What are the differences between Hadoop, MapReduce, and a Data Discovery Platform?
- How are these new sources of big data and analytic techniques and technology helping organizations find new truths and business opportunities?
What do you think?
For me it is all about the analytics and the new insights that can be gained and acted upon
First Steps in Exploring Social Media Analytics
As I talk with customers and colleagues the topic of social media analytics is often featured. Some customers have already got a strategy defined and are executing to a plan while others are at a more nascent stage but believe in the potential to have a direct and almost immediate connection to their customers.
I'll admit that I am somewhat of a social media novice so it will be a learning experience for me too. I am intrigued by the depth of analytics that may be possible. Only this month did I setup my profile on Facebook and I'm 47! I have been using Twitter more regularly of late, since our Teradata Universe conference and I probably look at it 3 or 4 times a day, depending on what's on my schedule for the day. I am finding some interesting, funny and informative updates each day, as I slowly expand the number of people I follow. It is really a mixture of friends and work related contacts at the moment. I have been a member of LinkedIn for a number of years and find it a useful resource from a professional perspective. I am within the first 1% of members who subscribed to this site (I received an email to that effect, that I was within the first 1 million sign ups when the site hit 100 million). Finally I am keen on blogging more frequently when I have something interesting to share (i.e. this! :-) ) I had stopped blogging for about 5 years at one point. I have also started with Flickr and YouTube as well. I'll be my own guinea pig in some ways as I explore and experiment on possible useful analytics in these social media channels.
However when most people think of Social Media and associated analytics, Facebook and Twitter are often mentioned first.
Focusing on Facebook and Twitter you see two very different levels of information. Twitter provides only basic, row level data. Facebook provides much more complex, relational data. We'll explore these in more detail in future posts.
Data from social media must be linked in three ways:
· Within the social media itself
· Across multiple social media
· Between social media and the bank’s core data
The most secure forms of linking are to use unique references: email addresses, IP addresses and telephone numbers. This can be supported by direct access methods (i.e. asking the user for their Twitter name, or persuading them to Like the bank on Facebook from within a known environment).
However, even then the confidence in the link must be evaluated and recorded: this information is user provided and may be wrong in some cases. The notion of a “soft match” should be adopted – we think that this is the same person, but we cannot be sure.
I would like to end this post with a recommendation to read the following white paper by John Lovett from Web Analytics Demystified Beyond Surface-Level Social Media. Lovett, who has written a book on Social Analytics , lays out a compelling vision for Deeper Social Analytics for companies. He clearly presents the value for companies to go beyond surface level analytics of likes, followers and friends and challenges you to ask deeper and more important questions. This white paper has been sponsored by Teradata Aster and is available for free from here.
In reading this white paper you will gain an understanding of the term 'Surface-Level Social Media' coined by John and how it is possible to gain competitive advantage even operating at this level. He will outline how Generation-Next Marketing is being powered by Social Analytics backed up with a number of interesting customer examples. He goes on to outline a 7 point strategy to build your deeper social media strategy. Finally John concludes with how unstructured data can yield valuable customer intelligence.
I found it to be very informative and well written and gave me a number of new insights and points to ponder. I would be interested in your thoughts on it too.
Enjoy!
Upcoming WebCast: Bridging the Gap--SQL and MapReduce for Big Analytics
On Tuesday May 29th, Teradata Aster will be hosting a web cast to discuss the Bridging the Gap--SQL and MapReduce for Big Analytics. Expected duration is 60 minutes and will start at 15:00 CET (Paris,Frankfurt) 14:00 UTC (London). You can register for free here.
We had run this seminar earlier in May but at a time which was more convenient for a US audience. The seminar was well attended and we received good feedback from attendees that encouraged us to rerun it again with some minor changes and at a time more convenient for people in Europe.
If you are considering a big data strategy, confused by all the hype that is out there, believe that Map Reduce = Hadoop? or Hive = SQL?, Then this is an ideal event for a business user to get a summary of the key challenges, the sort of solutions that are out there and the novel and innovative approach that Teradata Aster has taken to maximise time to value for companies considering their first Big Data initiatives.
I will be the moderator for the event, and will introduce Rick F. van der Lans, independent analyst and Managing Director of R20/Consultancy, based in the Netherlands. Rick is an independent analyst, consultant, author and lecturer specializing in Data Warehousing, Business Intelligence, Service Oriented Architectures, and Database Technology. He will be followed by Christopher Hillman from Teradata. Chris, is based in the United Kingdom and recently joined us a Principal Data Scientist. We will have time at the end to address questions from attendees.
During the session we will discuss the following topics:
- Understanding MapReduce vs SQL, UDF's, and other analytic techniques
- How SQL developers and business analysts can become "data scientists"
- Fitting MapReduce into your BI/DW technology stack
- Making the power of MapReduce available to the larger business community
Big Data Analytics SIG - Teradata Universe Dublin April 2012
At the recent Teradata Universe Conference held in Dublin, Duncan Ross, Simona Firmo and I organised a Special Interest Group (SIG) devoted to Big Data Analytics. We were lucky in the high quality speakers and panelists we had as well as the large attendance of delegates on the last day of the conference. I thought I would try to summarise my reflections from the session.
You can find an overview of the SIG here.
We kicked off with a presentation from Duncan, to set the scene for the session - Every journey starts with an idea / Seven ideas for starting your Big Data journey
Duncan chose to give his presentation via Prezi. You will find a copy of his presentation here. This was an interesting departure from the traditional M$ Powerpoint, and intrigued me enough to plan on using it for a future presentation myself. Certainly the transition between bullet points is more dramatic which some people like and others find nauseating in equal measure :-)
So the 7 ideas that Duncan presented were:


You can find an overview of the SIG here.
We kicked off with a presentation from Duncan, to set the scene for the session - Every journey starts with an idea / Seven ideas for starting your Big Data journey
Duncan chose to give his presentation via Prezi. You will find a copy of his presentation here. This was an interesting departure from the traditional M$ Powerpoint, and intrigued me enough to plan on using it for a future presentation myself. Certainly the transition between bullet points is more dramatic which some people like and others find nauseating in equal measure :-)
So the 7 ideas that Duncan presented were:
- Data exhaust
- Crowd Sourcing
- Location
- Gamification
- Self knowledge
- Quantified Self
- Consumer Data Locker
- Data Markets
- Open Data
I guess you could consider that 8 ideas Duncan! This presentation suitably warmed up the attendees for presentations from Tom Fastner on Do More with your Data: Deep Analytics. It is fantastic to learn about the scale at which eBay operates. The have an EDW on Teradata at 8+ PB, a Teradata system they call Singularity, for semi structured data at 42+ PB and unstructured data in Hadoop at 50+ PB. It was also interesting to see that the concurrent user population ranged from 500+ with the EDW, to 150+ with the singularity system to 5-10 on Hadoop. He also talked about their behaviour data flow and the value of compression to them.
This was followed by an equally interesting presentation by Professor Mark Whitehorn from the University of Dundee who was ably assisted by Chris Hillman a former student, who recently joined Teradata EMEA as a Principal Data Scientist. I found their presentation fascinating on their research work at Dundee on Proteomics: Science, Data Science and Analytics. Chris turned out to be a true geek, admitting to having built his own Hadoop cluster at home. Rest assured I have since converted him to the even more powerful and productive environment of Teradata Aster. I wasn't sure about his Hadoop cluster at home, but he sent me proof...

Their presentation outlined some of the possibilities of using Big Data analytics techniques on Proteomics, that could lead to dramatic improvements in drug discovery and shorten the drug development lifecycle. While this is a highly complicated area, it really outlines an innovative and possible very critical use case for big data analytics. I learnt that Mass Spectrometry generates 7GB of raw data per 4 hours and in excess of 15 TB per year that needs to be analysed and that's from only one machine! Teradata is working with university to bring this research forward. Stay tuned for more updates in this area in the future.
We then moved onto a panel session and our speakers where joined by Navdeep Alam from Mzinga, a Teradata Aster customer, who presented earlier in the week and our very own Dr. Judy Bayer from Teradata. We were hoping for a provocative panel session, so we set the title as: Big Data and Analytics for Greater Competitive advantage

Duncan and I brainstormed some questions in advance to kick off the panel session. The questions we posed were:
Q. What is the one word that sums up Big data for you?
Q. What makes a good Data Scientist?
- Curious,
- open mind,
- good communicator,
- creativity,
- passion for finding the stories in the data
Q. What is the most important Big Data Analytical Technology and why?
- MPP
- Fault Tolerance
- R
- Visualisation
- Path Analysis
- Ecosystem
Q. If Big Data Fails in 2012 what will be its cause?
- Data Silos
- Stupidity :-)
- Lack of skilled people
- Unreasonable expectations?
Q. If you were starting a Big Data project tomorrow (and could choose to do anything)
what would you do?
- Study the universe
- Proteomics
- Natural Language Processing
- Projects to benefit society
Did you attend this SIG? If so, what were your impressions?
Teradata Universe - Dublin
Back in Dublin, for the Teradata Universe Conference. Looking forward to talking with customers and colleagues from around Europe.
We have a booth for Aster, as part of the main Teradata booth on the Expo floor. Went to check it out today and get it ready. Looks good. You'll find me or Vic Winch or Mike Whelan there. Drop by to say hello. This is how it looks post setup



And from the outside, all quiet at the moment as it is Sunday afternoon

On the Wednesday Duncan Ross & I will host the Analytics for Big Data SIG
It is going to be a very busy week!
We have a booth for Aster, as part of the main Teradata booth on the Expo floor. Went to check it out today and get it ready. Looks good. You'll find me or Vic Winch or Mike Whelan there. Drop by to say hello. This is how it looks post setup



And from the outside, all quiet at the moment as it is Sunday afternoon

On the Wednesday Duncan Ross & I will host the Analytics for Big Data SIG
It is going to be a very busy week!
Navigating the hype around Big Data to yield business value from it
As the Big Data phenomenon continues to gather momentum, more and more organizations are starting to recognize the unexploited value in the vast amounts of data they hold. According to IDC, the Big Data technology and services market will grow to about $17 billion by 2015, seven times the growth rate of the overall IT market.
Despite the strong potential commercial advantage for business, developing an effective strategy to cope with existing and previously unexplored information could prove tough for many enterprises.
In many ways, this is because the term ‘Big Data’ itself is somewhat misleading. One definition is in terms of terabytes and petabytes of information that common database software tools cannot capture, manage and process within an acceptable amount of time. In reality, data volume is just one aspect of the discussion and arguably the most straightforward issue that needs to be addressed.
As Gartner points out; ‘the complexity, variety and velocity with which it is delivered combine to amplify the problem substantially beyond the simple issues of volume implied by the popular term Big Data.’ For this reason, ‘big’ really depends on the starting point and the size of the organization.
With so much being written about Big Data these days, it can prove difficult for enterprises to implement strategies that deliver on the promise of Big Data Analytics. For example I have read many online articles equating "MapReduce" with "Hadoop" and "Hadoop" with "Big Data".
MapReduce is, of course, a programming model that enables complex processing logic expressed in Java and other programming languages to be parallelised efficiently, thus permitting their execution on "shared nothing", scale-out hardware architectures and Hadoop is one implementation of the MapReduce programming model. There are other implementations of the MapReduce model – and there are other approaches to parallel processing, which are a better fit with many classes of analytic problems. However we rarely see these alternatives discussed.
Another interesting assertion I read and sometimes I am confronted with by customers new to Hadoop is the positioning of Hadoop as an alternative to existing, SQL-based technologies that is likely to displace – or even entirely replace – these technologies. This can often lead to an interesting discussion, but you could summarize that Hadoop lacks important capabilities found in a mature and sophisticated data warehouse RDBMS, for example: query re-write and cost-based query optimization; mixed-workload management; security, availability and recoverability features; support for transactions; etc., etc., etc.
There is, of course, a whole ecosystem springing-up around Hadoop – including HBase, Hive, Mahout and ZooKeeper, to name just four – and some commentators argue that in time these technologies may extend Hadoop to the point where this ecosystem could provide an alternative to existing Data Warehouse DBMS technology.
Possibly, but I would suggest that they have a long an arduous path to reach such a goal.
None of which is to say that Hadoop is not an extremely interesting and promising new technology – because clearly it is, and has role as enterprises embrace Big Data Analytics. There is evidence today, from leading e-business companies that Hadoop scales well - and has a unit-cost-of-storage that will increasingly make it possible for organizations to "remember everything", by enabling them to retain data whose value for analytics is as yet unproven.
Hadoop may become the processing infrastructure that enables us to process raw, multi-structured data and move it into a "Big Analytic" environment - like Teradata-Aster - that can more efficiently support high-performance, high concurrency manipulation of the data, whilst also providing for improved usability and manageability, so that we can bring this data to a wider audience. The final stage in this “Big Data value chain” will the see us move the insights derived from the processing of the raw multi-structured data in these "up stream" environments into the Data Warehouse, where it can most easily and most efficiently be combined with other data - and shared with the entire organization, so in order to maximize business value.
Teradata continues to invest in partnerships with leading Hadoop distributors Cloudera and Hortonworks - and to develop and enhance integration technology between these environments and the Teradata and Teradata-Aster platforms.
The fact that Big Data is discovery-oriented and its relative immaturity compared with traditional analytics, arguably means that it doesn’t sit well within the IT department because requirements can never be fully defined in advance. Neither should it logically fall to business analysts used to using traditional BI tools.
As a result, a new role has emerged for data scientists, who are not technologists but are also not afraid of leveraging technology. Rather than seeking an answer to a business question, this new professional is more concerned with what the question should be. The data scientist will look for new insights from data and will use it as a visualization tool not a reporting tool.
In future, many believe that having this type of individual on staff will also be key to generating maximum value from Big Data. In the meantime, the onus will invariably fall to the CIO to prepare and act for a changing Big Data landscape.
Customers can be assured that Teradata will continue to be their #1 strategic advisor for their data management and analytics. We continue to provide compelling and innovative solutions with Teradata Aster and Teradata IDW appliances. We will also work with best-in-class partners to provide choices in integrated solutions and reference architectures to help customers maintain competitive advantage with their data.
Signing back on...
Wow... Has it been nearly 5 years since my last post...
Well it has been an incredibly interesting and challenging time, Spent time with Informatica as VP of R&D for their Data Quality business. Met some great guys and learned a lot. Moved then to working for Pocket Kings (company behind Full Tilt Poker) as Director of Database systems. First time in my career on the customer/IT side of the fence. It was challenging, but working with very bright and committed people you learn a lot. It is also where I got the bug about Big Data through running an Aster Data nCluster 30+TB, 40+ nodes. After Teradata acquired Aster Data about a year ago I was lucky to get offered a position to spearhead the adoption of Aster Data in EMEA, both internally within Teradata and also with the Teradata customer base.
I am now living and working in the UK. I am still an Apple nut, still a Porsche nut, maybe still a nut period :-)
So what you can expect from this blog is my musings on Big Data and insight gleaned from working with customers to deliver business value from Big Data. I still also probably post about my passion for Porsche, I'm lucky to have a tweaked (540 bhp) 996 Turbo as my daily driver.
Enjoy and I welcome your feedback...
Well it has been an incredibly interesting and challenging time, Spent time with Informatica as VP of R&D for their Data Quality business. Met some great guys and learned a lot. Moved then to working for Pocket Kings (company behind Full Tilt Poker) as Director of Database systems. First time in my career on the customer/IT side of the fence. It was challenging, but working with very bright and committed people you learn a lot. It is also where I got the bug about Big Data through running an Aster Data nCluster 30+TB, 40+ nodes. After Teradata acquired Aster Data about a year ago I was lucky to get offered a position to spearhead the adoption of Aster Data in EMEA, both internally within Teradata and also with the Teradata customer base.
I am now living and working in the UK. I am still an Apple nut, still a Porsche nut, maybe still a nut period :-)
So what you can expect from this blog is my musings on Big Data and insight gleaned from working with customers to deliver business value from Big Data. I still also probably post about my passion for Porsche, I'm lucky to have a tweaked (540 bhp) 996 Turbo as my daily driver.
Enjoy and I welcome your feedback...
Oracle Ireland employee # 74 signing off...
I will shortly be starting my life outside Oracle after some 15 years there. My last day is today.
I've enjoyed it immensely and am proud of our accomplishments. It really doesn't seem like 15 years, and I have been lucky to work on some very exciting projects with some very clever people, many of whom have become friends. I look forward to hearing about all the new releases coming from Database Tools in the future.
Next it is two weeks holidays in France (I hope the weather gets better!) and then the beginning of my next adventure in a new company. More on that later.
I think I'll continue to blog on database tools topics.
I've enjoyed it immensely and am proud of our accomplishments. It really doesn't seem like 15 years, and I have been lucky to work on some very exciting projects with some very clever people, many of whom have become friends. I look forward to hearing about all the new releases coming from Database Tools in the future.
Next it is two weeks holidays in France (I hope the weather gets better!) and then the beginning of my next adventure in a new company. More on that later.
I think I'll continue to blog on database tools topics.
Access migration to Application Express without direct SQL Access
I got asked a question recently how to complete an Access migration when you don't have direct SQL access to the Oracle instance where Oracle Application Express is installed (e.g. apex.oracle.com)?
For dealing with the application part, it is not an issue as the Application Migration Workshop feature of APEX (3.0+) allows you to load the results from the Oracle Migration Workbench Exporter for Microsoft Access, so you can capture the meta data for Access Forms and Reports. You can even download a copy of the exporter from the workshop itself.
The challenge is really the schema and data migration part using Oracle SQL Developer (1.2+). By default SQL Developer expects to be able to make a SQL connection to the target Oracle database. However I did think about this use case as we were designing this new Migration Workbench tool. I will describe a solution below.
The only requirement, is that you have SQL access to any Oracle database (9iR2+), because the workbench is driven using an underlying migration repository. You could use the Express Edition of Oracle for this purpose, which is totally free, if you didn't have SQL access to an existing Oracle database.
So let me outline the main steps involved:
For dealing with the application part, it is not an issue as the Application Migration Workshop feature of APEX (3.0+) allows you to load the results from the Oracle Migration Workbench Exporter for Microsoft Access, so you can capture the meta data for Access Forms and Reports. You can even download a copy of the exporter from the workshop itself.
The challenge is really the schema and data migration part using Oracle SQL Developer (1.2+). By default SQL Developer expects to be able to make a SQL connection to the target Oracle database. However I did think about this use case as we were designing this new Migration Workbench tool. I will describe a solution below.
The only requirement, is that you have SQL access to any Oracle database (9iR2+), because the workbench is driven using an underlying migration repository. You could use the Express Edition of Oracle for this purpose, which is totally free, if you didn't have SQL access to an existing Oracle database.
So let me outline the main steps involved:
- Start SQL Developer 1.2
- Make sure you set the following preference: Tools -> Preferences -> Migration -> Generation Options: Least Privilege Schema Migration
- Create a connection to your Access database. Make sure you can browse the tables in the access database and see the data
- Export the table data to csv format: For each table you want to migrate, use the context menu associated with tables to export as csv format. Make sure you select an encoding that matches your target database. I try to keep everything in UTF-8
- Create a connection to an Oracle schema.
- Create a migration repository in this connection. You can do this via the context menu on a connection
- From your Access connection, context menu, select: Capture Microsoft Access. This will launch the exporter and initiate the capture step of the migration.
- Take your captured model and now create an Oracle (converted) model by selecting the captured model and via the context menu: Convert to Oracle Model
- With you converted model, you can now create an object creation script using the context menu: Generate
- The result of step 9 is presented in a SQL Worksheet, you can edit this to remove objects you are not interested in, then via File -> Save As, save the contents to a SQL file.
- Login to your APEX Workspace
- To execute the object creation script you have just created. Goto SQL Workshop -> SQL Scripts -> Upload.
- Once the script is uploaded, View it and select the RUN action. This should create all your schema objects, view the results to make sure all the object were create successfully. You now be able to view these schema objects in the SQL Workshop -> Object Browser.
- To load our CSV files we will use the Utilities -> Data Load/Unload -> Load, selecting Load Spreadsheet Data. You will do this for each table we want to load data into. Select Load To : Existing Table and Load From: Upload File. You may need to apply appropriate format masks to get the data to load properly.
- You should complete the schema and data migration part of your migration, prior to creating a migration project via the Application Migration Workshop.
- You may have some post migration cleanup steps, if you had access auto increment columns in your tables, you will need to reset the values of the sequences we have created.
- Another option to explore depending on your data, would be to export the data from Access tables as SQL INSERT statements, and then it just a simple matter of loading and run that SQL script via apex.
Its summer, time to bring the car out for a good drive
At the weekends, there is nothing better than taking out my Porsche for a long drive drive in the countryside. Much better, than my daily commute! I am a member of the Porsche Club of Ireland, and we had a great drive through the Wicklow mountains recently. The weather wasn't great but the scenery is still dramatic, lots of narrow twisting mountains roads to allow you to eke out the maximum enjoyment. It was fathers day so the kids decided they would both come with me, which was great.
 I think we had over 15 members cars out that day. Everybody is very friendly, with a passion for all things Porsche. We started out from the Porsche Center in Dublin and they graciously provided us with coffee before we started and allowed us to gaze over all the new models. Out of my price range of course!
I think we had over 15 members cars out that day. Everybody is very friendly, with a passion for all things Porsche. We started out from the Porsche Center in Dublin and they graciously provided us with coffee before we started and allowed us to gaze over all the new models. Out of my price range of course!
It was a real fun day and I look forward to the next event. We post the pictures from these "drives" on the club web site.

 I think we had over 15 members cars out that day. Everybody is very friendly, with a passion for all things Porsche. We started out from the Porsche Center in Dublin and they graciously provided us with coffee before we started and allowed us to gaze over all the new models. Out of my price range of course!
I think we had over 15 members cars out that day. Everybody is very friendly, with a passion for all things Porsche. We started out from the Porsche Center in Dublin and they graciously provided us with coffee before we started and allowed us to gaze over all the new models. Out of my price range of course!It was a real fun day and I look forward to the next event. We post the pictures from these "drives" on the club web site.

Oracle Database Plugin for the Eclipse Data Tools Platform
As a further commitment to the Eclipse Community, Oracle announces an early adopter release of the Oracle Database Plugin for Eclipse Data Tools Platform. This plugin extends the Eclipse Data Tools Platform to connect to and work with Oracle database objects. The initial plugin supports the ability to connect to Oracle Databases, navigate through all database objects, execute stored procedures and functions, and view textual and graphical execution plans.

This release has been tested against DTP 1.0. We will revise the plugin as required once DTP 1.5 is released as part of the imminent Eclipse Euorpa release.
Oracle has published a Statement of Direction which outlines our future plans.
Feedback from the community is important to us so Oracle has created a forum on OTN to provide a means for this feedback to be collected and allow Oracle to respond. Assuming a positive level of interest from the community, we would seek to formally join the DTP project for the purpose of contributing to the Connectivity, Model Base, SQL Development Tools and particularly the Enablement subproject to provide specialized support for the Oracle Database.


This release has been tested against DTP 1.0. We will revise the plugin as required once DTP 1.5 is released as part of the imminent Eclipse Euorpa release.
Oracle has published a Statement of Direction which outlines our future plans.
Feedback from the community is important to us so Oracle has created a forum on OTN to provide a means for this feedback to be collected and allow Oracle to respond. Assuming a positive level of interest from the community, we would seek to formally join the DTP project for the purpose of contributing to the Connectivity, Model Base, SQL Development Tools and particularly the Enablement subproject to provide specialized support for the Oracle Database.
Oracle Database Migration has reached the next level!
SQL Developer 1.2 is now production and with it our new integrated migration workbench. Find out more information on OTN here. Over the last 6 months or so as I have talked about this new product, I used the tag line "Taking database migration to the next level", well... I think we are there now. We are the first database vendor to provide an integrated migration tool into a developers IDE with all of the resulting productivity benefits this brings.

 The SQL Developer Migration Workbench is the tool to aid in the migration of third party databases onto the Oracle platform. This tool allows you to migrate your existing Microsoft Access, Microsoft SQL Server and MySQL databases (including schema objects, data and stored procedures/functions) to Oracle.
The SQL Developer Migration Workbench is the tool to aid in the migration of third party databases onto the Oracle platform. This tool allows you to migrate your existing Microsoft Access, Microsoft SQL Server and MySQL databases (including schema objects, data and stored procedures/functions) to Oracle.
Features of this production release include:
I am very proud of what my team has achieved with this release. A lot of work over the past year has gone into it. This is only the beginning, expect further innovative releases from the database tools team in the future.
I would like to thank our early adopters who provided some very constructive feedback. Hopefully you see the results of your feedback in this production release.

Features of this production release include:
- Enhanced user interface - This release harnesses the enhanced GUI environment of SQL Developer and works seamlessly with other SQL Developer components. This means that users have one tool to browse third-party databases, migrate selected objects to Oracle and then work with them.
- Existing SQL Developer users should find the Migration Workbench familiar and easy to use.
- Quick Migration Wizard provides the easiest and quickest means of doing a database migration.
- Step driven migration offers control at each stage of the migration process.
- Fine grain migration support provides users with the ability to select specific objects for migration.
- Least privilege migration - The ability to migrate objects from source to target without the need for dba rights. The workbench will migrate objects it has rights to view so does not require any special privileges to run.
- Platform Supported:
- Supports Microsoft Access versions 97, 2000, 2002/XP, 2003
- Microsoft SQL Server 7, 2000, 2005
- MySQL versions 3, 4, 5.
- Parallel Online data move - The ability to move the data using a number of parallel connections for increased throughput.
- Offline data move script generation - Generates scripts to allow for export of source data and import to target database of offline data move. We also support offline capture as well.
- Language Translation Features - Supports translation of stored programs, procedures, functions, triggers, constraints and views defined in Transact SQL or Microsoft Access SQL.
- Translation scratch editor - An interactive editing facility for Transact SQL and Microsoft Access SQL allowing for instant translation to PL/SQL or SQL. This editor supports both single-statement translation and translation of entire SQL scripts.
- Translation difference viewer - Inline difference viewer for examining translated SQL. This viewer provides color coded side-by-side comparison of translated SQL to display semantic similarities between the source and translated code.
- Any many more interesting features for you to find out about....
I am very proud of what my team has achieved with this release. A lot of work over the past year has gone into it. This is only the beginning, expect further innovative releases from the database tools team in the future.
I would like to thank our early adopters who provided some very constructive feedback. Hopefully you see the results of your feedback in this production release.
Access Migration Tutorial
Are you considering migrating that Microsoft Access application to Oracle Application Express? Well read on...
Hopefully you are aware of Oracle SQL Developer and that we have redeveloped the Migration Workbench and integrated it tightly with Oracle SQL Developer. An early adopter version of this is available now and will be production very soon. More of that in a subsequent post.
With Oracle Application Express 3.0 we introduced the Application Migration Workshop to assist with migrating your Access Forms & Reports. When I talk about this solution, I get asked do we have a step by step guide or methodology for such migrations. So, we have produced a migration tutorial to address this and have published it on OTN.
We have taken the Microsoft Access sample application, Northwind Traders and migrated it to Oracle Application Express. The tutorial covers this in step by step detail. Following this tutorial would be a useful exercise for any user that wishes to undertake migrating their applications from Microsoft Access to Oracle Application Express. We have called the converted application Southwind Wholesalers. :-)
You can see it running on apex.oracle.com and we have also provided it as a packaged application so you can examine it in detail.
Hopefully you are aware of Oracle SQL Developer and that we have redeveloped the Migration Workbench and integrated it tightly with Oracle SQL Developer. An early adopter version of this is available now and will be production very soon. More of that in a subsequent post.
With Oracle Application Express 3.0 we introduced the Application Migration Workshop to assist with migrating your Access Forms & Reports. When I talk about this solution, I get asked do we have a step by step guide or methodology for such migrations. So, we have produced a migration tutorial to address this and have published it on OTN.
We have taken the Microsoft Access sample application, Northwind Traders and migrated it to Oracle Application Express. The tutorial covers this in step by step detail. Following this tutorial would be a useful exercise for any user that wishes to undertake migrating their applications from Microsoft Access to Oracle Application Express. We have called the converted application Southwind Wholesalers. :-)
You can see it running on apex.oracle.com and we have also provided it as a packaged application so you can examine it in detail.
Updated Oracle SQL Developer Migration Workbench Early Adopter Release
We have updated the early adopter release of Oracle SQL Developer Migration Workbench today on OTN. You can get it from here. This is our final preview release, before we go production. We are now functionally complete for this initial production release and are now focused on fixing our final "show stopper" bugs. We have had good feedback from our user community via our feedback application and also via the Workbench forum. They have uncovered a number of bugs, most of which we have now addressed (Oracle9i as a repository and Access data migration issues for example) and the remaining ones we will resolve prior to production. I encourage everybody to update to this latest release and continue to provide us with feedback.
I have been working extensively with different builds of the Migration Workbench these past couple of weeks as we closed in on our goal to refresh the early adopter version. In my "biased" opinion is it looking much stronger and I would like to outline some of the new features in this updated early adopter release.
Quick Migrate
In the orginal Migration Workbench we had a wizard driven approach to simplify migrations and I felt it was important to bring this functionality back. With our Quick Migrate wizard, I believe we have improved from the original wizard, since we will leverage our least priviliege migration capabilities, assume sensible defaults and create/remove our migration repository.
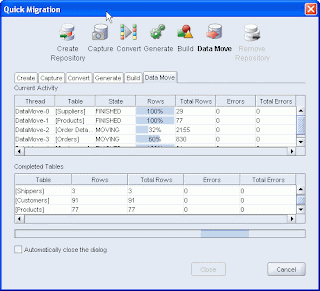
So if you have a schema on SQL Server or a single Access mdb file to migrate to an existing Oracle schema, this should be the easiest and quickest migration option for you. Another nice feature, if you are doing an access migration, is that we have added command line support to our exporter so, we will automatically launch the correct Access exporter for the Access connection that you specify.
Offline Capture
This was a popular feature with our consultants and partner technical services folks, with the original Workbench, as it allowed them to work remote from the customer/partner. We have now added back in that feature.
Migration Reports
We have added in some initial migration reports available under Reports->Shared Reports. This will be an area we will add to into the future, as we can mine our rich metadata repository to provide you with useful information. If you have suggestions for additional reports let me know. I will also publish more details about our repository, so you can develop your own migration reports as well. Maybe we should have a competition for the best contributed report? I think we have a couple of 1GB USB keys left over from our Database Developer Day in Dublin I could use as prizes.
Translation Scratch Editor
We have reworked this feature extensively. I originally wanted to add a feature that would enable you to validate our translated SQL. As we worked through different iterations of how best to implement this feature, we came up with the idea about leveraging our existing Worksheet capabilities, which I think is very cool and I am very pleased with how this turned out.
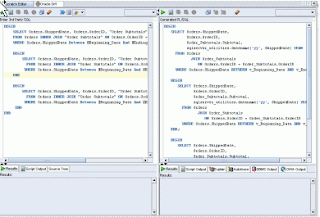
We have also done a lot of work to improve incremental capture and improve our filtering capabilities from our early adopter release. We have integrated our MySQL parser from the original Migration Workbench and will extend its capabilities in subsequent releases to be as functional as our new TSQL parser and also support SQL statement level translation. (workaround for now, within the scratch editor, is just wrap the SQL statement in a procedure). We have also implemented the ability to update your Access mdb file, to create link tables to point to your newly migrated schema. This was also a feature of the original workbench. We hope to add some additional usability tweaks to create an ODBC OSN on the fly and provide a select list of known Oracle DSN. Hopefully that will make it in before production as well.
We have made fixes to ensure correct generation order for pl/sql procedures to resolve dependencies, so more pl/sql procedures should compile correctly first time. We made improvement to handle inline DDL statements correctly. Temporary tables, normal tables and other DDL are lifted out of the body of the procedure/function and are created separately.
Now for the final bug fix push by the development teams in Dublin and Bangalore. Our QA team, have been doing a good job verifying our fixes and closing off our bugs. The teams have been working hard on this for many months now and I believe we are in touching distance of reaching our goal. It will be very exciting for me personally to see this second generation migration tool reach production. We'll all need some time off when this is done to recharge...
I have been working extensively with different builds of the Migration Workbench these past couple of weeks as we closed in on our goal to refresh the early adopter version. In my "biased" opinion is it looking much stronger and I would like to outline some of the new features in this updated early adopter release.
Quick Migrate
In the orginal Migration Workbench we had a wizard driven approach to simplify migrations and I felt it was important to bring this functionality back. With our Quick Migrate wizard, I believe we have improved from the original wizard, since we will leverage our least priviliege migration capabilities, assume sensible defaults and create/remove our migration repository.

So if you have a schema on SQL Server or a single Access mdb file to migrate to an existing Oracle schema, this should be the easiest and quickest migration option for you. Another nice feature, if you are doing an access migration, is that we have added command line support to our exporter so, we will automatically launch the correct Access exporter for the Access connection that you specify.
Offline Capture
This was a popular feature with our consultants and partner technical services folks, with the original Workbench, as it allowed them to work remote from the customer/partner. We have now added back in that feature.
Migration Reports
We have added in some initial migration reports available under Reports->Shared Reports. This will be an area we will add to into the future, as we can mine our rich metadata repository to provide you with useful information. If you have suggestions for additional reports let me know. I will also publish more details about our repository, so you can develop your own migration reports as well. Maybe we should have a competition for the best contributed report? I think we have a couple of 1GB USB keys left over from our Database Developer Day in Dublin I could use as prizes.
Translation Scratch Editor
We have reworked this feature extensively. I originally wanted to add a feature that would enable you to validate our translated SQL. As we worked through different iterations of how best to implement this feature, we came up with the idea about leveraging our existing Worksheet capabilities, which I think is very cool and I am very pleased with how this turned out.

We have also done a lot of work to improve incremental capture and improve our filtering capabilities from our early adopter release. We have integrated our MySQL parser from the original Migration Workbench and will extend its capabilities in subsequent releases to be as functional as our new TSQL parser and also support SQL statement level translation. (workaround for now, within the scratch editor, is just wrap the SQL statement in a procedure). We have also implemented the ability to update your Access mdb file, to create link tables to point to your newly migrated schema. This was also a feature of the original workbench. We hope to add some additional usability tweaks to create an ODBC OSN on the fly and provide a select list of known Oracle DSN. Hopefully that will make it in before production as well.
We have made fixes to ensure correct generation order for pl/sql procedures to resolve dependencies, so more pl/sql procedures should compile correctly first time. We made improvement to handle inline DDL statements correctly. Temporary tables, normal tables and other DDL are lifted out of the body of the procedure/function and are created separately.
Now for the final bug fix push by the development teams in Dublin and Bangalore. Our QA team, have been doing a good job verifying our fixes and closing off our bugs. The teams have been working hard on this for many months now and I believe we are in touching distance of reaching our goal. It will be very exciting for me personally to see this second generation migration tool reach production. We'll all need some time off when this is done to recharge...
Oracle Application Express 3.0 a credible alternative to Microsoft Access?
I hope most people know by now that Oracle Application Express (APEX) 3.0 has gone production, is available for download from OTN and our hosted instance, apex.oracle.com had also been upgraded to 3.0. There has been some positive reviews in the press recently, here are links to a number of them:
Oracle Updates Application Express Tool
Oracle updates free Web development tool
Oracle has big ambitions for Application Express
Oracle improves free tool for building Web Applications
Oracle Application Express 3.0 Touts Access Migration
Most customers I talk with have problems with Access and are looking at alternatives, which I guess is the reason I am talking with them in the first place. However, Microsoft Access is a popular desktop database and was updated recently as part of the Office 2007. That said, it is desktop centric and more suited (optimized?) for productivity applications used by individuals or small groups.
On our OTN page about the Application Migration Workshop we have published a high level feature comparison of Access and Oracle APEX.
Is Oracle Application Express 3.0 a credible alternative to Microsoft Access?
What do you think?
Oracle Updates Application Express Tool
Oracle updates free Web development tool
Oracle has big ambitions for Application Express
Oracle improves free tool for building Web Applications
Oracle Application Express 3.0 Touts Access Migration
Most customers I talk with have problems with Access and are looking at alternatives, which I guess is the reason I am talking with them in the first place. However, Microsoft Access is a popular desktop database and was updated recently as part of the Office 2007. That said, it is desktop centric and more suited (optimized?) for productivity applications used by individuals or small groups.
On our OTN page about the Application Migration Workshop we have published a high level feature comparison of Access and Oracle APEX.
Is Oracle Application Express 3.0 a credible alternative to Microsoft Access?
What do you think?
Oracle SQL Developer Migration Workbench Early Adopter Release
Last week we released on OTN the early adopter release of the Oracle SQL Developer Migration Workbench. You can find more details about it here. It was a very important release for us, and marks the start of a new generation of migration tools.
It is nearly 10 years ago when the original Oracle Migration Workbench was released, we supported migrating SQL Server 6.5 to Oracle8 then. At that time, I believe we were the first to introduce a GUI tool. Previously we had provided a series of migration scripts (shell based + SQL) and a stored procedure converter utility. We went on to add support for Access, Sybase, Informix, DB2 utilizing the same user interface by leveraging our plugin architecture. Over the years we have seen our database competitors and others release similar migration tools for their databases.
With this release, I believe we have made the same dramatic shift again that we did back in 1998. By integrating our migration tool as a extension of SQL developer (our very popular tool for database developers) we have provided our users with a modern intuitive UI tightly integrated into an IDE, that should make users even more productive as they carry out database migrations. I don't believe any of our competitors have delivered such tight integration.
This initial release supports Microsoft SQL Server, Access and MySQL. We are introducing support for migrating Microsoft SQL Server 2005 with this release. These third party databases represents the most popular downloads for our existing Oracle Migration Workbench. We will add further platforms in the future. We have also architected this solution, to make it even easier to extend and leverage the rich core migration functionality that we have developed. We hope that others will also extend this tool going forward adding support for additional databases.
The focus now, is on completing some features which missed the cut for the early adopter release, (more on that in a later post) , getting feedback from our user community and fixing as many reported bugs to ensure the highest possible quality release, when we go production, as SQL Developer 1.2. I encourage you to try it out and provide us with feedback. We have setup a comment application which you can provide us with feedback. You can access it here.
Some of my favorite features of this new release includes:
It is nearly 10 years ago when the original Oracle Migration Workbench was released, we supported migrating SQL Server 6.5 to Oracle8 then. At that time, I believe we were the first to introduce a GUI tool. Previously we had provided a series of migration scripts (shell based + SQL) and a stored procedure converter utility. We went on to add support for Access, Sybase, Informix, DB2 utilizing the same user interface by leveraging our plugin architecture. Over the years we have seen our database competitors and others release similar migration tools for their databases.
With this release, I believe we have made the same dramatic shift again that we did back in 1998. By integrating our migration tool as a extension of SQL developer (our very popular tool for database developers) we have provided our users with a modern intuitive UI tightly integrated into an IDE, that should make users even more productive as they carry out database migrations. I don't believe any of our competitors have delivered such tight integration.
This initial release supports Microsoft SQL Server, Access and MySQL. We are introducing support for migrating Microsoft SQL Server 2005 with this release. These third party databases represents the most popular downloads for our existing Oracle Migration Workbench. We will add further platforms in the future. We have also architected this solution, to make it even easier to extend and leverage the rich core migration functionality that we have developed. We hope that others will also extend this tool going forward adding support for additional databases.
The focus now, is on completing some features which missed the cut for the early adopter release, (more on that in a later post) , getting feedback from our user community and fixing as many reported bugs to ensure the highest possible quality release, when we go production, as SQL Developer 1.2. I encourage you to try it out and provide us with feedback. We have setup a comment application which you can provide us with feedback. You can access it here.
Some of my favorite features of this new release includes:
- Least privilege migration - You no longer need dba privileges
- Online Data Move - We have enhanced the online data move and provide parallel data move and the degree of parallelism is configurable
- New T/SQL parser - We have completing rewritten our T/SQL parser. If I'm honest, it was long over due, but this new parser, provides us with the right foundation for a much greater level of automation in converting complex objects (stored procedures, views, triggers)
- Translation Scratch Editor - allows for the instant translation of Transact SQL or Microsoft Access SQL to PL/SQL or SQL.
- Translation Difference Viewer - a color-coded side-by-side viewer to display semantic similarities between the source and translated code.